")
")
")
Search and Indexing
Here you can retrieve information about and configure the Search engine, the installed index languages, the available parsers and the queue of documents to be indexed.
Search engine

Entries count: displays the number of elements in the index
Repository: the folder that stores the index
Include / Exclude patterns: inclusion / exclusion filename patterns to restrict what documents will be processed
Include / Exclude patterns (metadata only): inclusion / exclusion filename patterns to restrict what documents will be processed for just the metadata
On error, mark unindexable: in case of error, the document gets marked as unindexable
Sorting: defines the ordering used to process the documents
Batch: number of documents processed at each indexing
Parsing Timeout: max. time to process a single document
Max text: maximum number of chars stored in the index for a single document
Max text file size: max size parsed for text files, expressed in KB
Save: all the changes will be stored
Unlock: the Full-text index will be unlocked
Purge: removes from the index those entries that refer to deleted files
Reschedule all for indexing: all the documents are rescheduled for being indexed again
Drop index: deletes the actual index
Check: will be shown a report regarding the Full-Text Index status
Filters
The way your texts are processed during the indexing depends on filters. Filters examine a stream of tokens and keep them, transform or discard them, or create new ones. Filters may be combined in a chain, where the output of one is input to the next. Such a sequence of filters is used to match query results and build the index. In the Filters tab you see the list of all available filters, of course you can reorder them and disable/enable them.

If you expand a filter you can also configure it's specific parameters, here is a brief description of the available filters:
Filter: stemmer
Uses the document's language to stem the words.
Example: "Take papers everywhere" produces: "take", "paper", "every"
Filter: worddelimiter
Splits tokens at word delimiters. The rules for determining delimiters are determined as follows:
- A change in case within a word: "CamelCase" -> "Camel", "Case". This can be disabled by setting splitOnCaseChange="0".
- A transition from alpha to numeric characters or vice versa: "Gonzo5000" -> "Gonzo", "5000" "4500XL" -> "4500", "XL". This can be disabled by setting splitOnNumerics="0".
- Non-alphanumeric characters (discarded): "hot-spot" -> "hot", "spot"
- A trailing "'s" is removed: "O'Reilly's" -> "O", "Reilly"
- Any leading or trailing delimiters are discarded: "--hot-spot--" -> "hot", "spot"
| Configurations | |
|---|---|
| types | the configuration file defining the characters types, the path is relative to <LDOC_HOME>/repository/index/logicaldoc/conf |
| generateWordParts | (integer, default 1) If non-zero, splits words at delimiters. For example:"CamelCase", "hot-spot" -> "Camel", "Case", "hot", "spot" |
| generateNumberParts | (integer, default 1) If non-zero, splits numeric strings at delimiters:"1947-32" ->"1947", "32" |
| splitOnCaseChange | (integer, default 1) If 0, words are not split on camel-case changes:"BugBlaster-XL" -> "BugBlaster", "XL". Example 1 below illustrates the default (non-zero) splitting behavior. |
| splitOnNumerics | (integer, default 1) If 0, don't split words on transitions from alpha to numeric:"FemBot3000" -> "Fem", "Bot3000" |
| catenateWords | (integer, default 0) If non-zero, maximal runs of word parts will be joined: "hot-spot-sensor's" -> "hotspotsensor" |
| catenateNumbers | (integer, default 0) If non-zero, maximal runs of number parts will be joined: 1947-32" -> "194732" |
| catenateAll | (0/1, default 0) If non-zero, runs of word and number parts will be joined: "Zap-Master-9000" -> "ZapMaster9000" |
| preserveOriginal | (integer, default 0) If non-zero, the original token is preserved: "Zap-Master-9000" -> "Zap-Master-9000", "Zap", "Master", "9000" |
| stemEnglishPossessive | (integer, default 1) If 1, strips the possessive "'s" from each subword |
Filter: ngram
Generates n-gram tokens of sizes in the given range. Note that tokens are ordered by position and then by gram size.
Example: "four score" produces: "f", "o", "u", "r", "fo", "ou", "ur", "s", "c", "o", "r", "e", "sc", "co", "or", "re"
| Configurations | |
|---|---|
| minGramSize | (integer, default 1) The minimum gram size |
| maxGramSize | (integer, default 2) The maximum gram size |
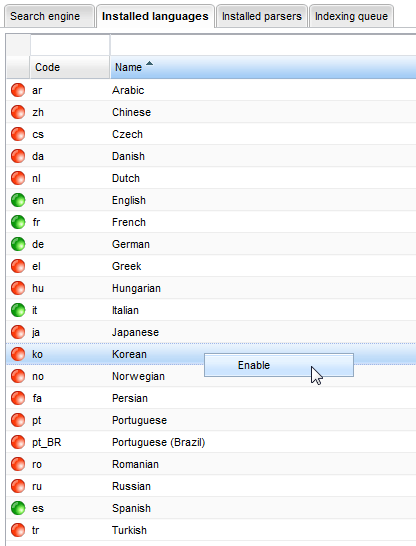
Languages
In this panel, you can see all the available system's languages. You can enable or disable each of them, right-clicking on the item and select the Enable or Disable option.
Parsers
In this panel, you can see all the system parsers.

History
In this panel, there are the indexation events. Here you can see successes and errors:

Indexing queue
In this panel, you can see all documents not already indexed. You can make unindexable a document by right-clicking on the item and then selecting the Mark unindexable option.

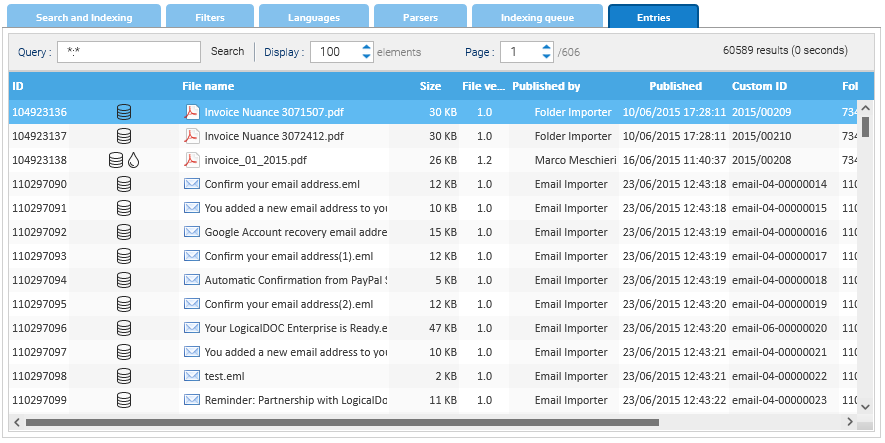
Entries
In this panel, you can do low-level searches to inspect the entries contained in the full-text index