")
")
")
Rilevatore lingua
Il modello di rilevamento della lingua identifica automaticamente la lingua di un documento in base al suo contenuto testuale. Ciò consente al sistema di classificare i documenti per lingua e di supportare flussi di lavoro di elaborazione specifici per ciascuna lingua.
Il modello si basa su un'implementazione pre-addestrata fornita da Apache OpenNLP e non richiede addestramento all'interno del sistema.
Come funziona il modello di rilevamento della lingua
Il modello analizza il testo di input e prevede la lingua più probabile utilizzando schemi statistici appresi da grandi insiemi di dati multilingue.
Testa il modello
Per testare rapidamente il modello, puoi fare clic con il pulsante destro del mouse sul modello, selezionare Interroga il modello e compilare i campi richiesti (Contenuto).
In questo esempio, il contenuto utilizzato è:
Ich lehre euch den Übermenschen. Der Mensch ist etwas, das überwunden werden soll. Was habt ihr getan, ihn zu überwinden?
... Alles Wesen bisher schuf etwas über sich hinaus; und ihr wollt die Ebbe dieses grossen Schwindens sein und lieber noch zum Tiere zurückgehen,
als den Menschen überwinden?
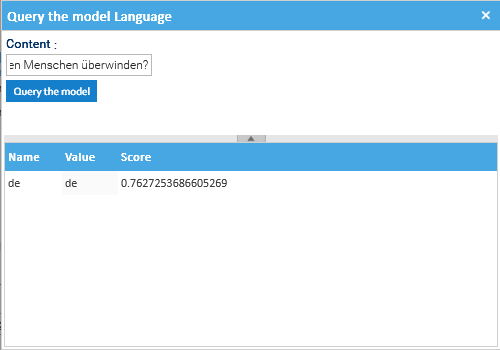
La lingua rilevata viene restituita insieme al relativo punteggio di affidabilità.