")
")
")
Classificatore
Il classificatore è un componente del linguaggio naturale che assegna una categoria a un dato testo in base al suo contenuto. In questo sistema, il classificatore viene addestrato utilizzando coppie di dati di esempio, in cui ogni coppia contiene un'etichetta di categoria e una frase di esempio che termina con uno spazio seguito da un punto ( .). Ciò consente al classificatore di apprendere modelli e parole chiave comunemente associati a intenti o comandi specifici.
Come Funzione il Classificatore
Il classificatore viene addestrato utilizzando esempi etichettati, in cui ogni riga include una categoria e una frase che riflette tale categoria. Questo crea un modello che può successivamente confrontare i nuovi input con ciò che ha appreso. Per addestrare il modello, il sistema si aspetta un file CSV contenente una sola colonna. Ogni riga di questa colonna deve seguire un formato molto specifico:
<categoria><TAB><testo che termina con uno spazio seguito da un punto>.
Esempi:
SEARCHDOC Find any files about budget .
SEARCHDOC Locate docs about paper .
SEARCHDOC Retrieve documents matching "news" .
GETDOC Can you get doc with ID 1233587 .
GETDOC I need to access file with id 29679 .
GETDOC Show doc with id 299 .
SEARCHFILE File called "mywork.docx" .
SEARCHFILE Get document called invoice.pdf .
SEARCHFILE Open doc titled booklet.txt .
Panoramica della Configurazione del Classificatore
Questa sezione descrive i campi di configurazione chiave per il modello di classificatore utilizzato nel sistema NLP. Queste impostazioni definiscono il comportamento del classificatore durante l'addestramento e l'interpretazione dell'input dell'utente.
Proprietà
La scheda Proprietà nell'interfaccia del classificatore contiene le impostazioni di configurazione principali che definiscono il comportamento del classificatore durante l'addestramento e l'inferenza. Questi parametri influenzano l'elaborazione del testo di input, l'estrazione delle caratteristiche e l'applicazione delle regole specifiche della lingua. La corretta configurazione di questi campi garantisce una classificazione accurata ed efficiente.
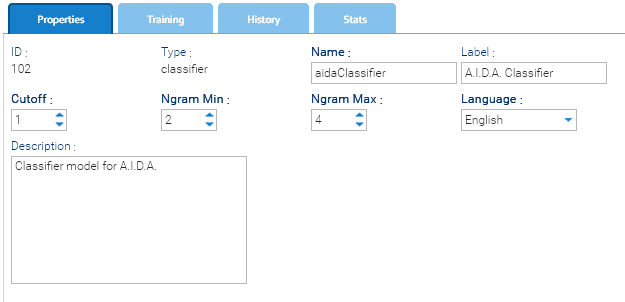
- Cutoff: un valore di soglia utilizzato durante l'addestramento per filtrare le caratteristiche a bassa probabilità. Un valore inferiore indica che vengono utilizzate più caratteristiche ; un valore superiore rende il modello più restrittivo.
- Ngram Min: la dimensione minima degli n-grammi (sequenze di parole) da considerare durante l'addestramento (ad esempio, 2 = bigrammi).
- Ngram Max: la dimensione massima degli n-grammi da includere durante l'addestramento (ad esempio, 4 = sequenze fino a 4 parole).
- Lingua: la lingua del dataset di addestramento (ad esempio, inglese). Questo aiuta il sistema a caricare le stop word e le regole di elaborazione appropriate.