")
")
")
Embedder
I modelli di classe Embedder consentono la mappatura di interi documenti in vettori di lunghezza fissa, rendendo possibile la loro rappresentazione in uno spazio vettoriale continuo. Ciò facilita il confronto e la manipolazione efficienti dei dati testuali nell'elaborazione del linguaggio naturale (NLP), come le ricerche semantiche.
Come funziona l'Embedder
La trasformazione del contenuto di un documento in un vettore viene realizzata tramite l'algoritmo Doc2Vec. Questo manuale non è la sede adatta per trattare i dettagli di questa tecnica, ma è possibile online trovare molta letteratura sull'argomento.
In poche parole, Doc2Vec utilizza una particolare rete neurale per creare una rappresentazione numerica di un documento (il vettore) che in genere verrà memorizzato in un Vector Store; documenti simili saranno rappresentati da due vettori diversi ma adiacenti nello spazio vettoriale multidimensionale.
L'Embedder viene addestrato utilizzando paragrafi di testo scritti in linguaggio naturale, ogni paragrafo terminato da un punto seguito da una riga vuota:
Esempio:
She quickly dropped it all into a bin, closed it with its wooden
lid, and carried everything out. She had hardly turned her back
before Gregor came out again from under the couch and stretched
himself.
This was how Gregor received his food each day now, once in the
morning while his parents and the maid were still asleep, and the
second time after everyone had eaten their meal at midday as his
parents would sleep for a little while then as well, and Gregor's
sister would send the maid away on some errand. Gregor's father and
mother certainly did not want him to starve either, but perhaps it
would have been more than they could stand to have any more
experience of his feeding than being told about it, and perhaps his
sister wanted to spare them what distress she could as they were
indeed suffering enough.
Panoramica della configurazione dell'Embedder
Questa sezione descrive i campi di configurazione chiave per il modello Embedder. Queste impostazioni definiscono il comportamento del modello durante l'addestramento e come interpreta l'input dell'utente.
Proprietà
La scheda Proprietà nell'interfaccia dell'embedder contiene le impostazioni di configurazione principali che definiscono il comportamento dell'embedder durante l'addestramento e l'incorporamento. Questi parametri influenzano l'elaborazione del testo in input.
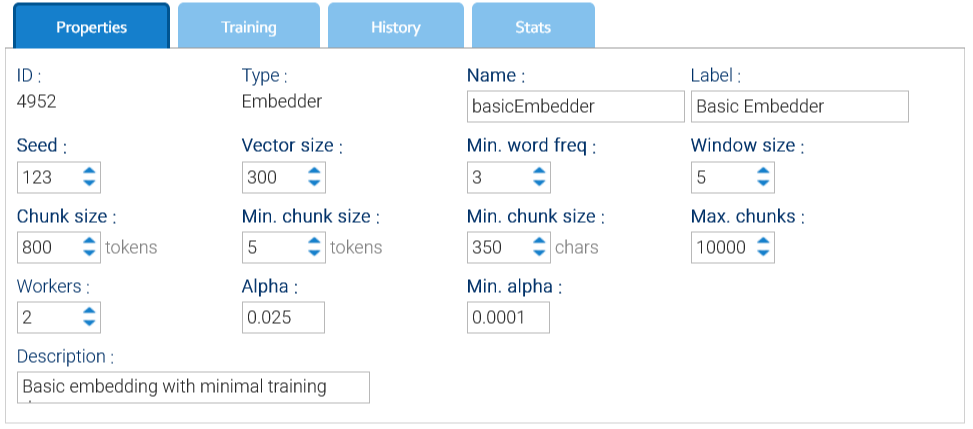
- Seme: un valore utilizzato per la generazione di numeri casuali
- Esecutori: numero di processi utilizzati per l'addestramento
- Dimensione finestra: dimensione della finestra utilizzata dall'algoritmo Doc2Vec
- Dimensione vettore: numero di elementi in ogni singolo vettore, meglio se maggiore di 300
- Frequenza minima parole: le parole che compaiono con un numero inferiore a questo verranno scartate
- Numero massimo di frammenti: ogni documento è suddiviso in blocchi di token, qui si specifica il numero massimo di blocchi ammessi
- Dimensione blocco: numero target di token in un singolo blocco
- Numero minimo di frammenti: Dimensione del frammento: numero minimo di token e caratteri in un singolo blocco
- Alfa: tasso di apprendimento iniziale (la dimensione degli aggiornamenti del peso in un modello di apprendimento durante l'addestramento), il valore predefinito è 0,025
- Alfa min.: il tasso di apprendimento scenderà linearmente al valore alfa minimo in tutte le epoche di inferenza, il valore predefinito è 0,0001