")
")
")
Clasificador
El clasificador es un componente del lenguaje natural que asigna una categoría a un texto determinado en función de su contenido. En este sistema, el clasificador se entrena utilizando pares de datos de ejemplo, donde cada par contiene una etiqueta de categoría y una oración de ejemplo que termina con un espacio seguido de un punto ( .). Esto permite al clasificador aprender patrones y palabras clave que se asocian comúnmente con intenciones o comandos específicos.
Cómo funciona el clasificador
El clasificador se entrena con ejemplos etiquetados, donde cada línea incluye una categoría y una oración que la refleja. Esto genera un modelo que posteriormente puede comparar nuevas entradas con lo aprendido.
Para entrenar el modelo, el sistema espera un archivo CSV con una sola columna. Cada línea de esta columna debe seguir un formato muy específico:
<categoría><TAB><texto que termina con un espacio seguido de un punto>.
Ejemplos:
SEARCHDOC Find any files about budget .
SEARCHDOC Locate docs about paper .
SEARCHDOC Retrieve documents matching "news" .
GETDOC Can you get doc with ID 1233587 .
GETDOC I need to access file with id 29679 .
GETDOC Show doc with id 299 .
SEARCHFILE File called "mywork.docx" .
SEARCHFILE Get document called invoice.pdf .
SEARCHFILE Open doc titled booklet.txt .
Descripción general de la configuración del clasificador
Esta sección describe los campos de configuración clave del modelo de clasificador utilizado en el sistema de PLN. Estos ajustes definen el comportamiento del clasificador durante el entrenamiento y su interpretación de la entrada del usuario.
Propiedades
La pestaña Propiedades de la interfaz del clasificador contiene los ajustes de configuración principales que definen el comportamiento del clasificador durante el entrenamiento y la inferencia. Estos parámetros influyen en el procesamiento del texto de entrada, la extracción de características y la aplicación de las reglas específicas del idioma. La correcta configuración de estos campos garantiza una clasificación precisa y eficiente.
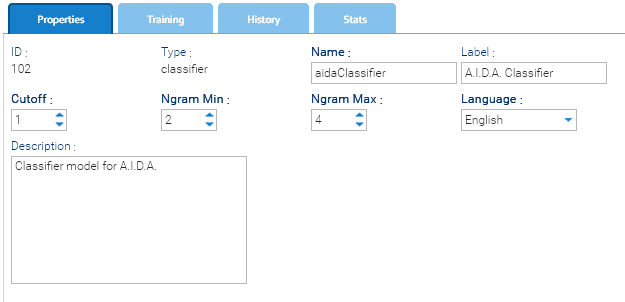
- Cutoff: valor umbral utilizado durante el entrenamiento para filtrar características de baja probabilidad. Un valor bajo significa que se utilizan más características; un valor alto hace que el modelo sea más estricto.
- Ngram Min: tamaño mínimo de n-gramas (secuencias de palabras) a considerar durante el entrenamiento (p. ej., 2 = bigramas).
- Ngram Max: tamaño máximo de n-gramas a incluir durante el entrenamiento (p. ej., 4 = secuencias de hasta 4 palabras).
- Idioma: idioma del conjunto de datos de entrenamiento (p. ej., inglés). Esto ayuda al sistema a cargar las palabras vacías y las reglas de procesamiento adecuadas.