")
")
")
Detector de idioma
El modelo de detección de idioma identifica automáticamente el idioma de un documento a partir de su contenido textual. Esto permite al sistema clasificar los documentos por idioma y admitir flujos de trabajo de procesamiento específicos para cada idioma.
El modelo se basa en una implementación preentrenada proporcionada por Apache OpenNLP y no requiere entrenamiento dentro del sistema.
Cómo funciona el modelo de detección de idiomas
El modelo analiza el texto de entrada y predice el idioma más probable utilizando patrones estadísticos aprendidos a partir de grandes conjuntos de datos multilingües.
Prueba el modelo
Para probar rápidamente el modelo, haga clic con el botón derecho sobre él, seleccione Consultar el modelo y complete los campos necesarios (Contenido).
En este ejemplo, el contenido utilizado es:
Ich lehre euch den Übermenschen. Der Mensch ist etwas, das überwunden werden soll. Was habt ihr getan, ihn zu überwinden?
... Alles Wesen bisher schuf etwas über sich hinaus; und ihr wollt die Ebbe dieses grossen Schwindens sein und lieber noch zum Tiere zurückgehen,
als den Menschen überwinden?
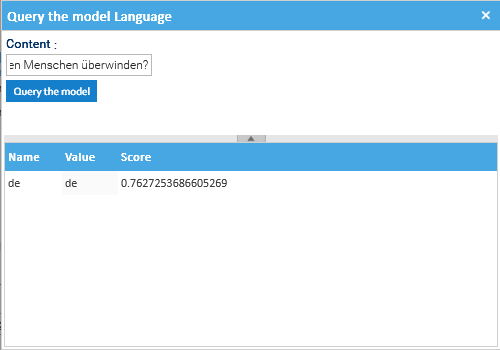
El idioma detectado se devuelve junto con su índice de confianza.