")
")
")
Red neuronal
Una red neuronal es un modelo de IA que enseña a las computadoras a procesar datos modelándolos según el funcionamiento del cerebro humano. Es un tipo de proceso de aprendizaje automático (AA), llamado aprendizaje profundo, que utiliza nodos o neuronas interconectados en una estructura en capas similar al cerebro humano. Crea un sistema adaptativo que las computadoras utilizan para aprender de sus errores y mejorar continuamente. Por lo tanto, las redes neuronales artificiales intentan resolver problemas complejos.
Cómo funciona una red neuronal
La arquitectura de una red neuronal se inspira en el cerebro humano. Las células cerebrales humanas, llamadas neuronas, forman una red compleja y altamente interconectada que se envía señales eléctricas entre sí para ayudar a los humanos a procesar información. De igual manera, una red neuronal artificial está compuesta por neuronas artificiales que trabajan juntas para resolver un problema. Las neuronas artificiales son módulos de software, llamados nodos, y las redes neuronales artificiales son programas de software o algoritmos que, esencialmente, utilizan la computación para resolver cálculos matemáticos.
Una red neuronal básica tiene neuronas artificiales interconectadas en tres niveles:
Capa de Entrada
La información del mundo exterior ingresa a la red neuronal en la capa de entrada. Los nodos de entrada procesan los datos, los analizan o categorizan y los transmiten a la siguiente capa.
Capa Oculta
Las capas ocultas toman su información de la capa de entrada o de otras capas ocultas. Las redes neuronales artificiales pueden tener un gran número de capas ocultas. Cada capa oculta analiza la salida de la capa anterior, la procesa y la pasa a la siguiente.
Capa de Salida
La capa de salida devuelve el resultado final de todo el procesamiento de datos a través de la red neuronal artificial. Puede tener uno o más nodos. Por ejemplo, si tenemos un problema de clasificación binaria (sí/no), la capa de salida tendrá un solo nodo de salida, que devolverá 1 o 0. Sin embargo, si tenemos un problema de clasificación multiclase, la capa de salida podría constar de varios nodos de salida.
Arquitectura de redes neuronales profundas
Las redes neuronales profundas, o redes de aprendizaje profundo, tienen múltiples capas ocultas con millones de neuronas artificiales conectadas entre sí. Un número, llamado peso, representa las conexiones entre cada nodo. El peso es positivo si un nodo estimula a otro y negativo si lo suprime. Los nodos con valores de peso más altos ejercen una mayor influencia sobre los demás.
En teoría, las redes neuronales profundas pueden asignar cualquier tipo de entrada a cualquier tipo de salida. Sin embargo, requieren más entrenamiento que otros métodos de aprendizaje automático. Requieren millones de ejemplos de datos de entrenamiento, en comparación con los cientos o miles que necesita una red más simple.
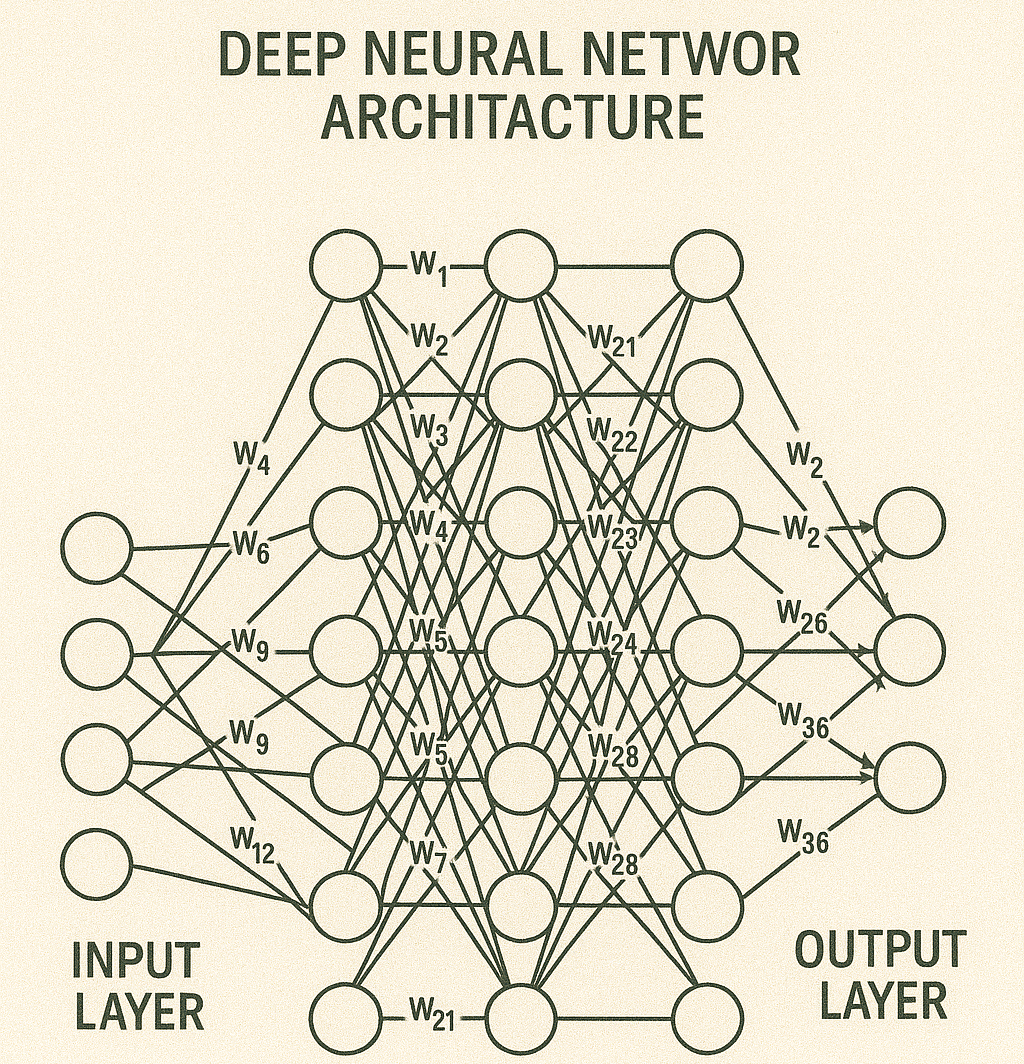
Función de Activación
Cada nivel define una función matemática llamada Función de Activación. Esta función recibe la entrada del nivel anterior multiplicada por el peso y genera la salida para el siguiente nivel.
| Activation Function | Graphic |
|---|---|
| CUBE | 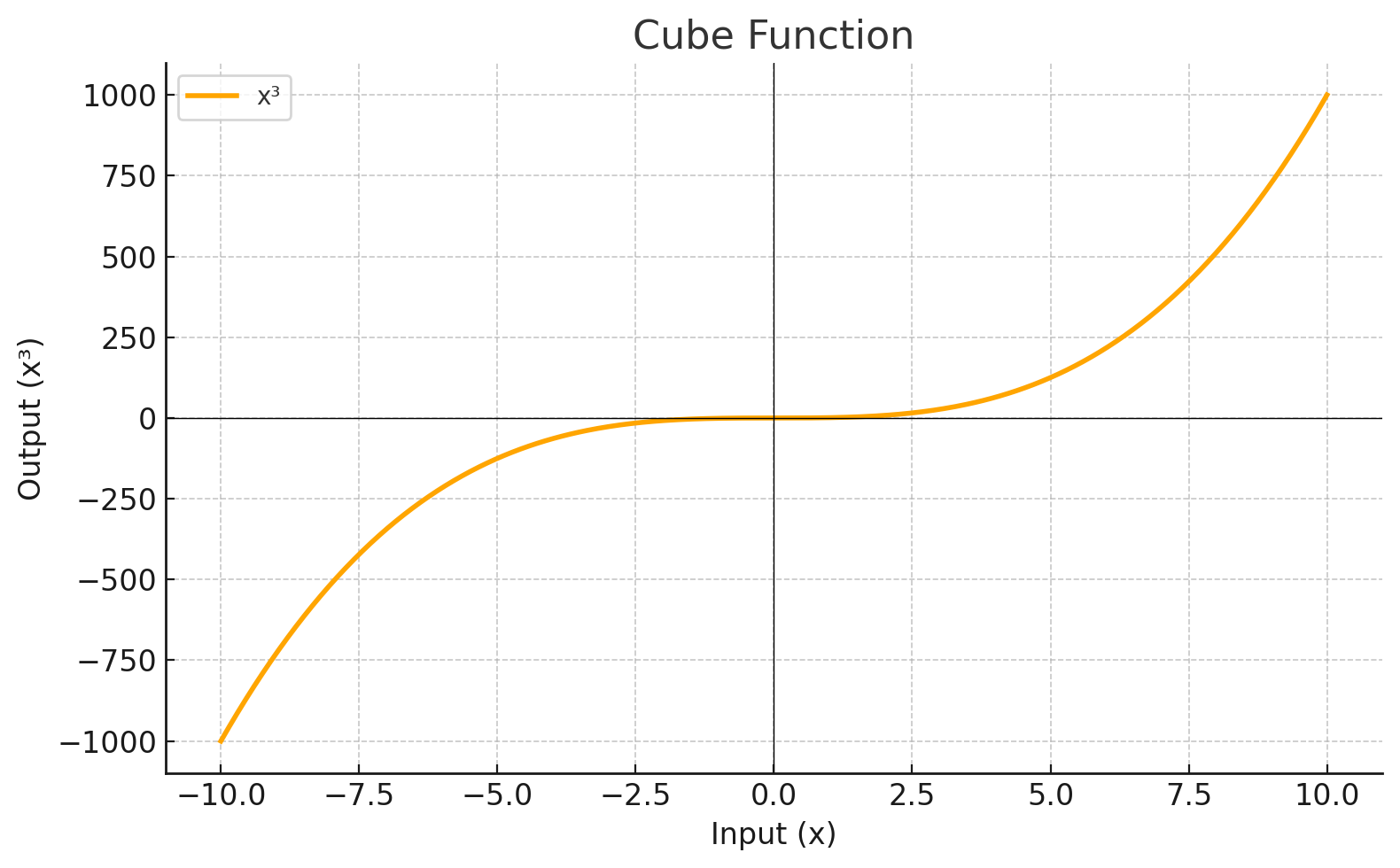
|
| ELU | 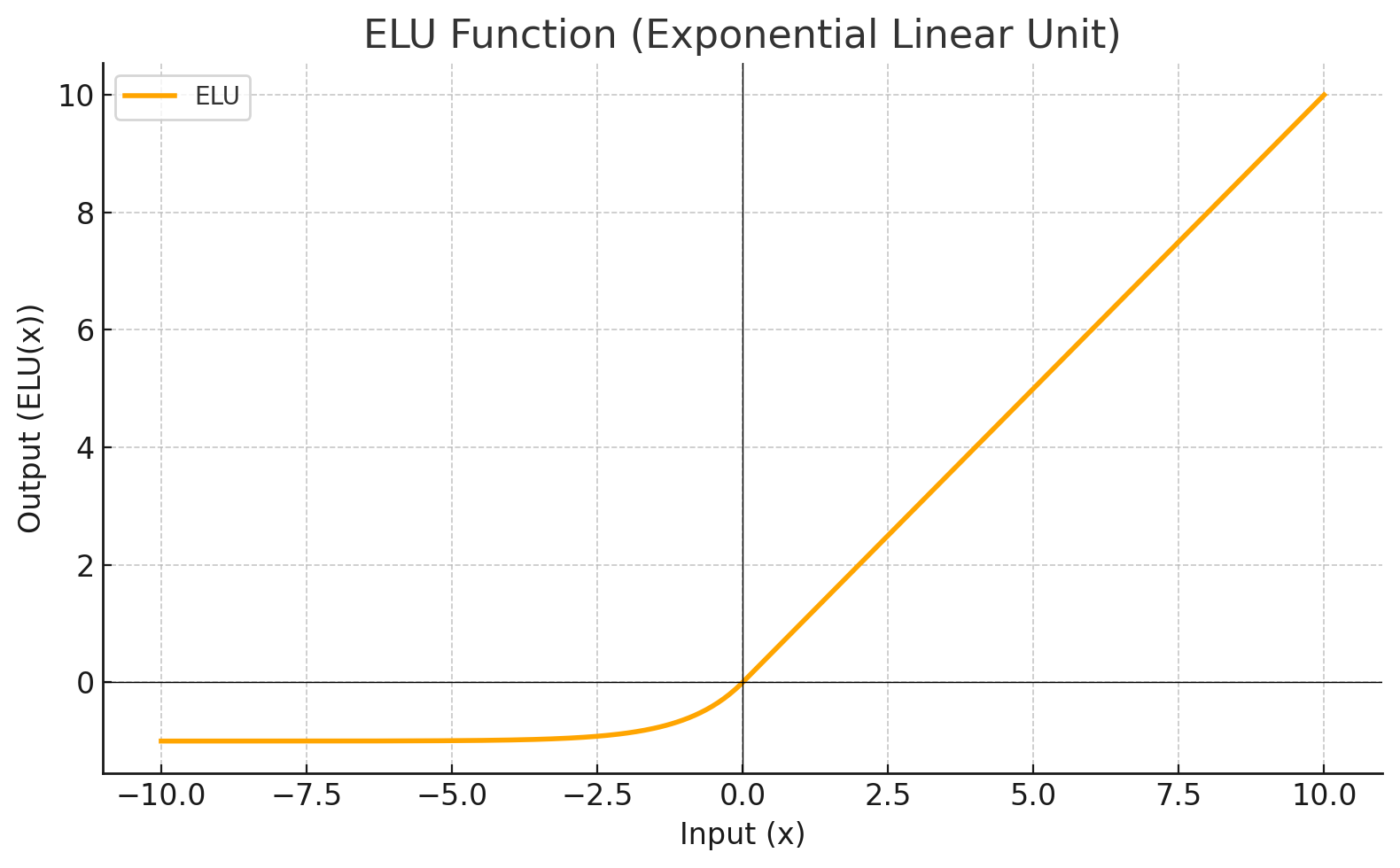
|
| HARDSIGMOID | 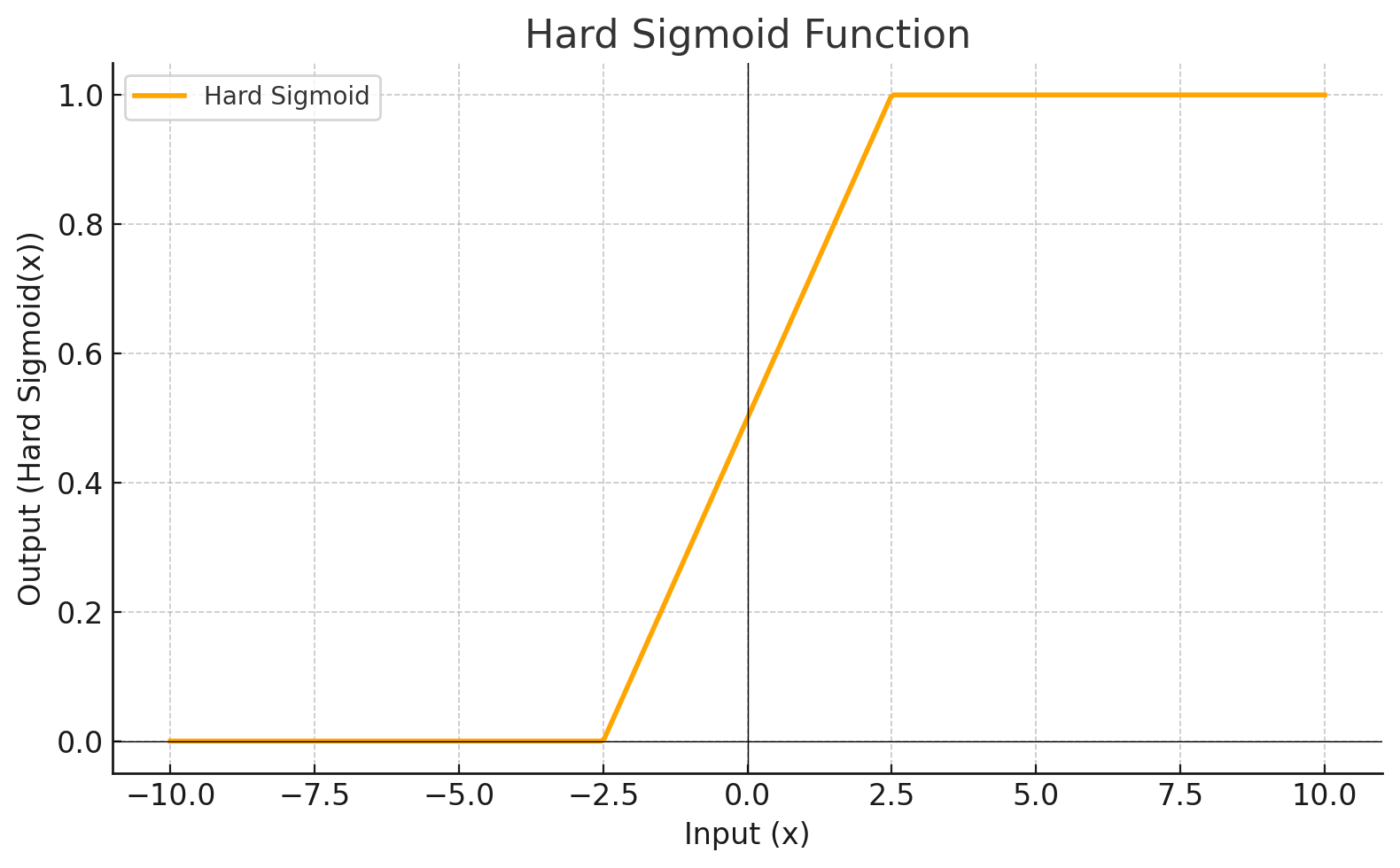
|
| HARDTANH | 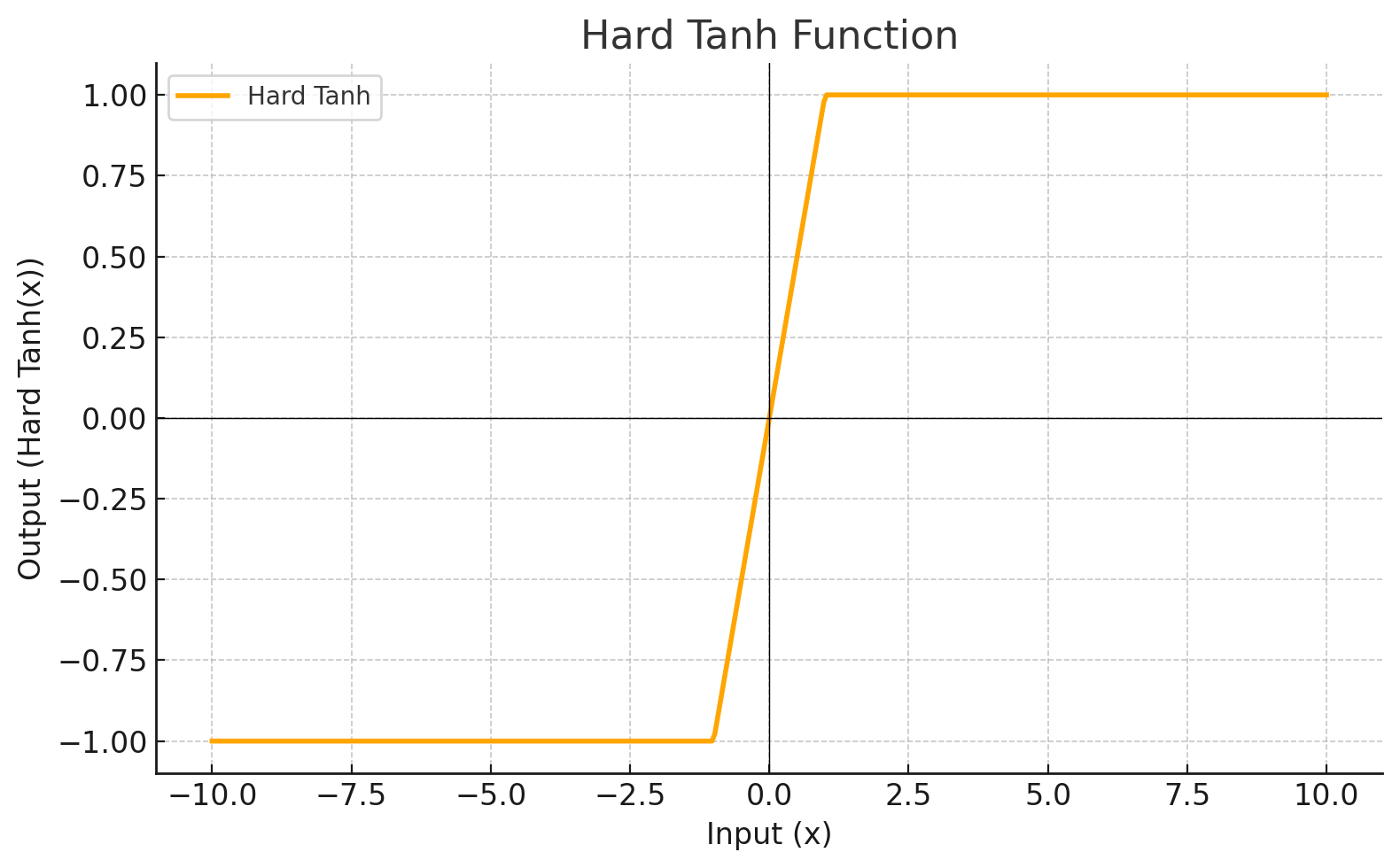
|
| IDENTITY | 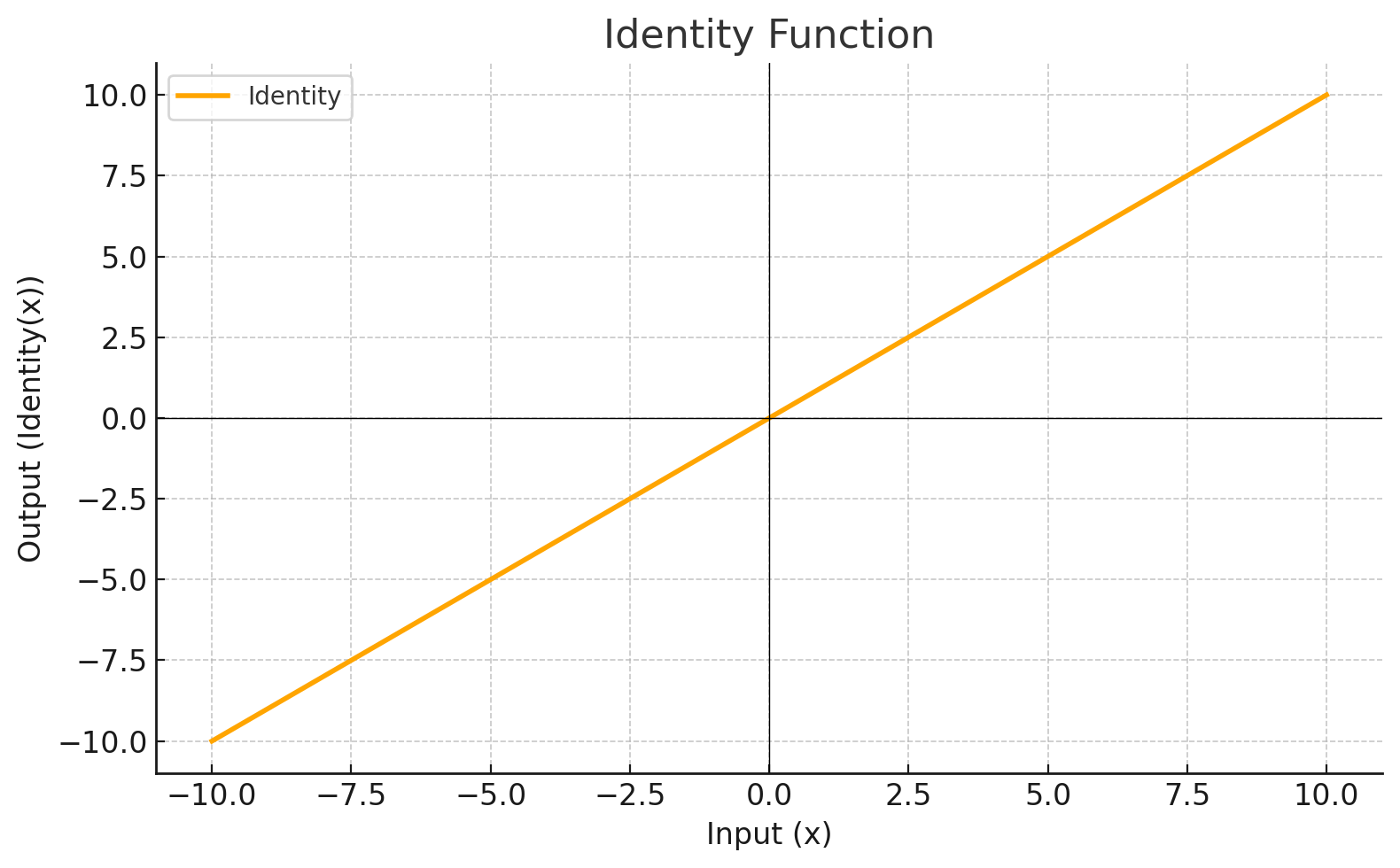
|
| LEAKYRELU | 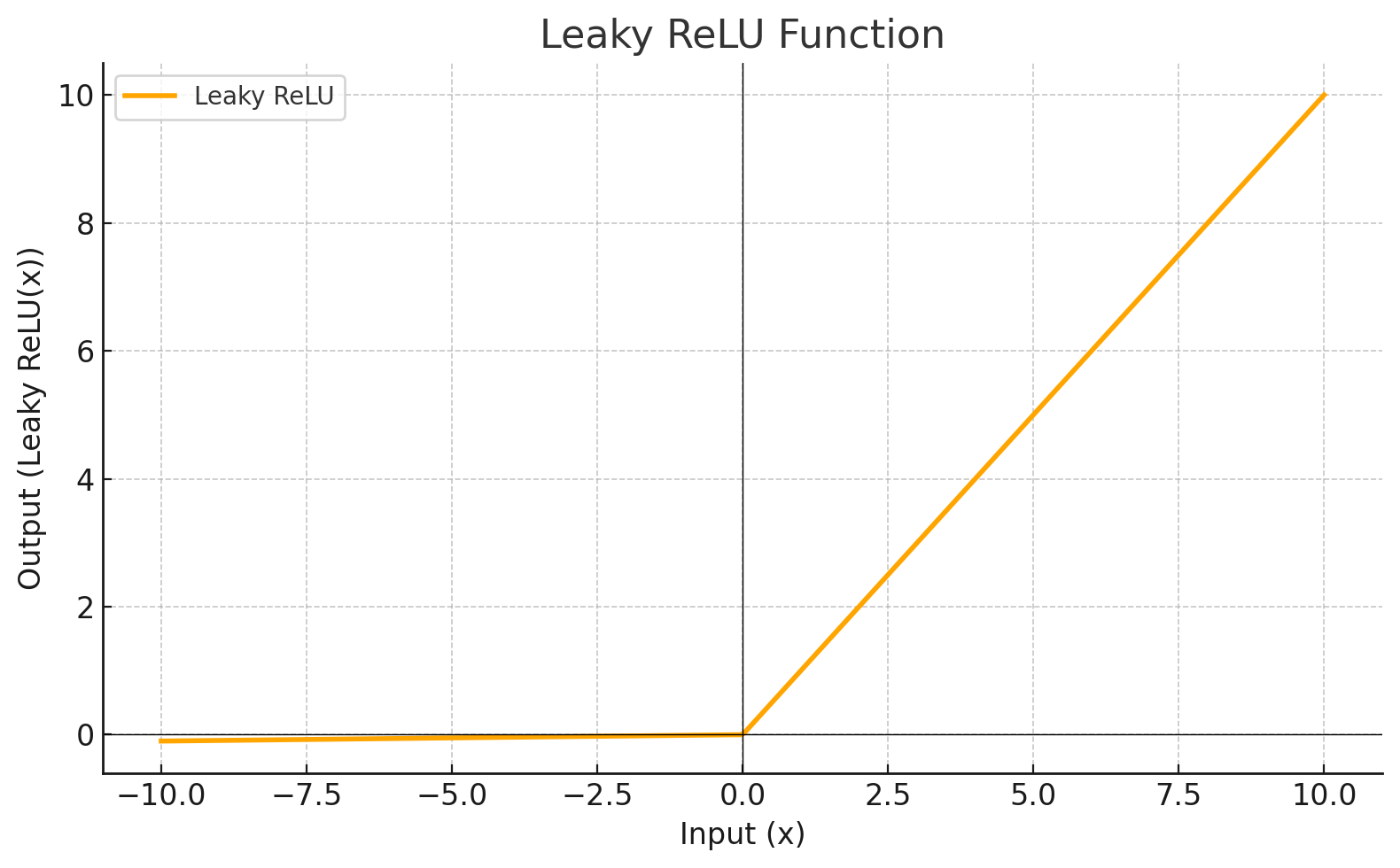
|
| RATIONALTANH | 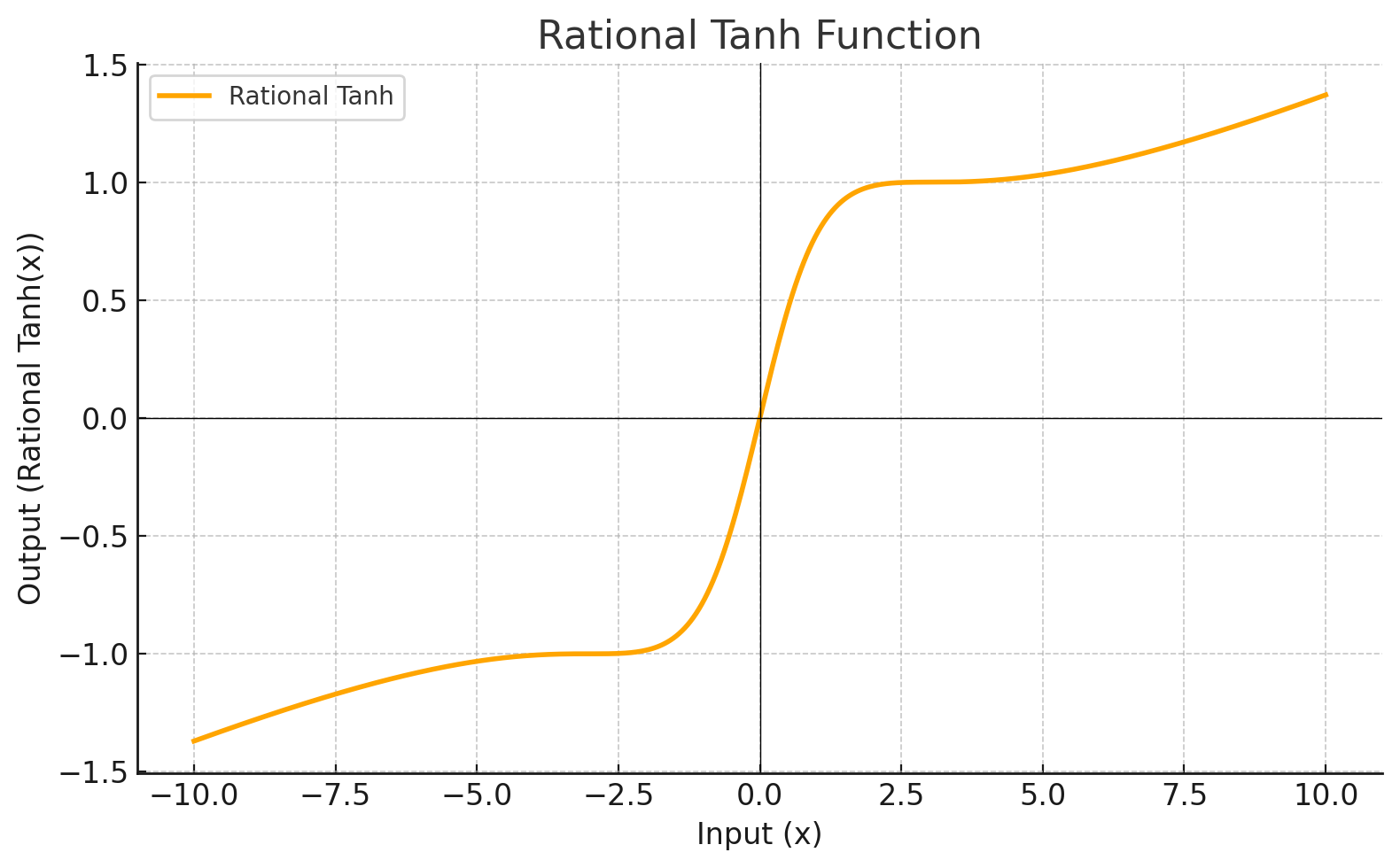
|
| RELU | 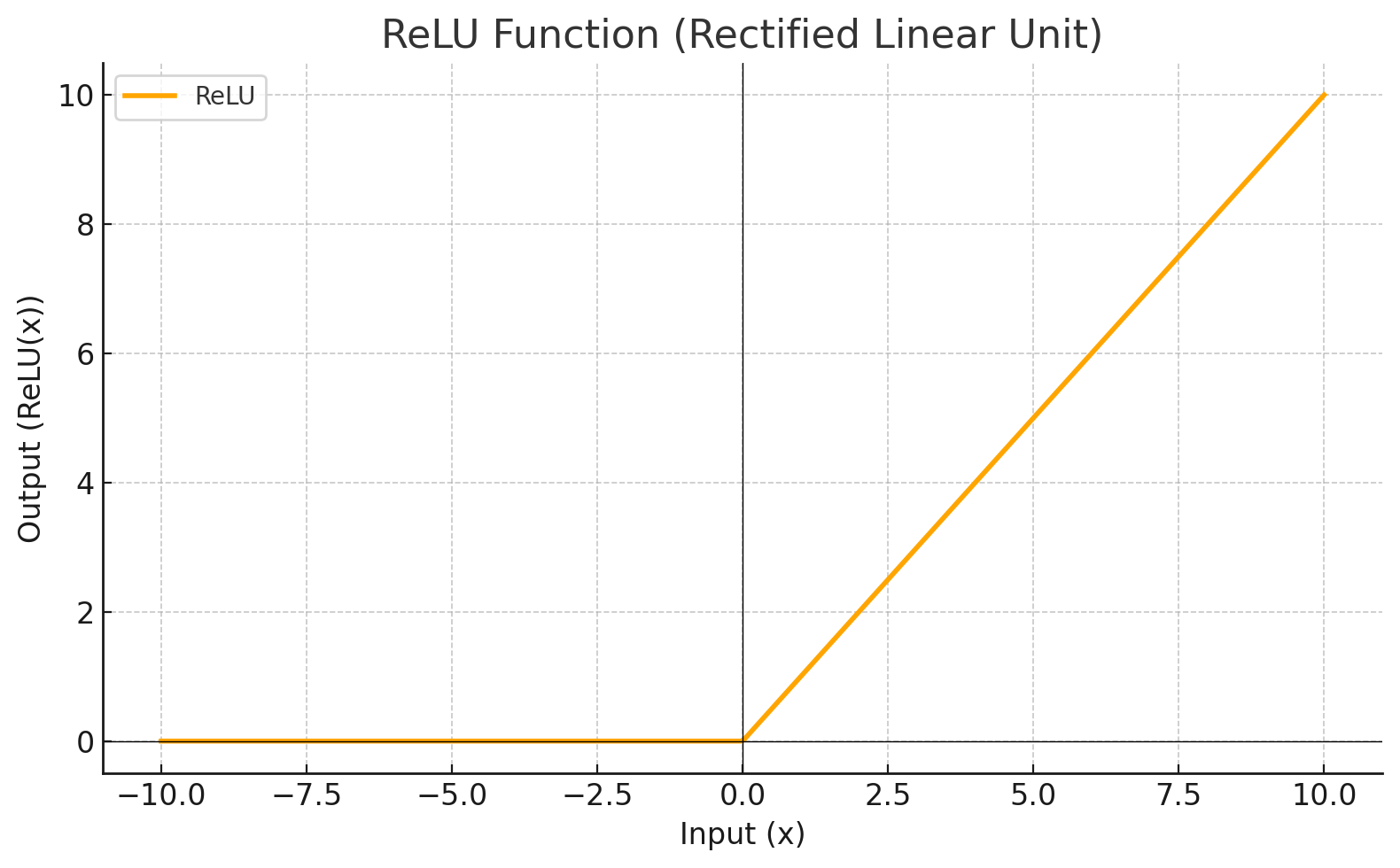
|
| RELU6 | 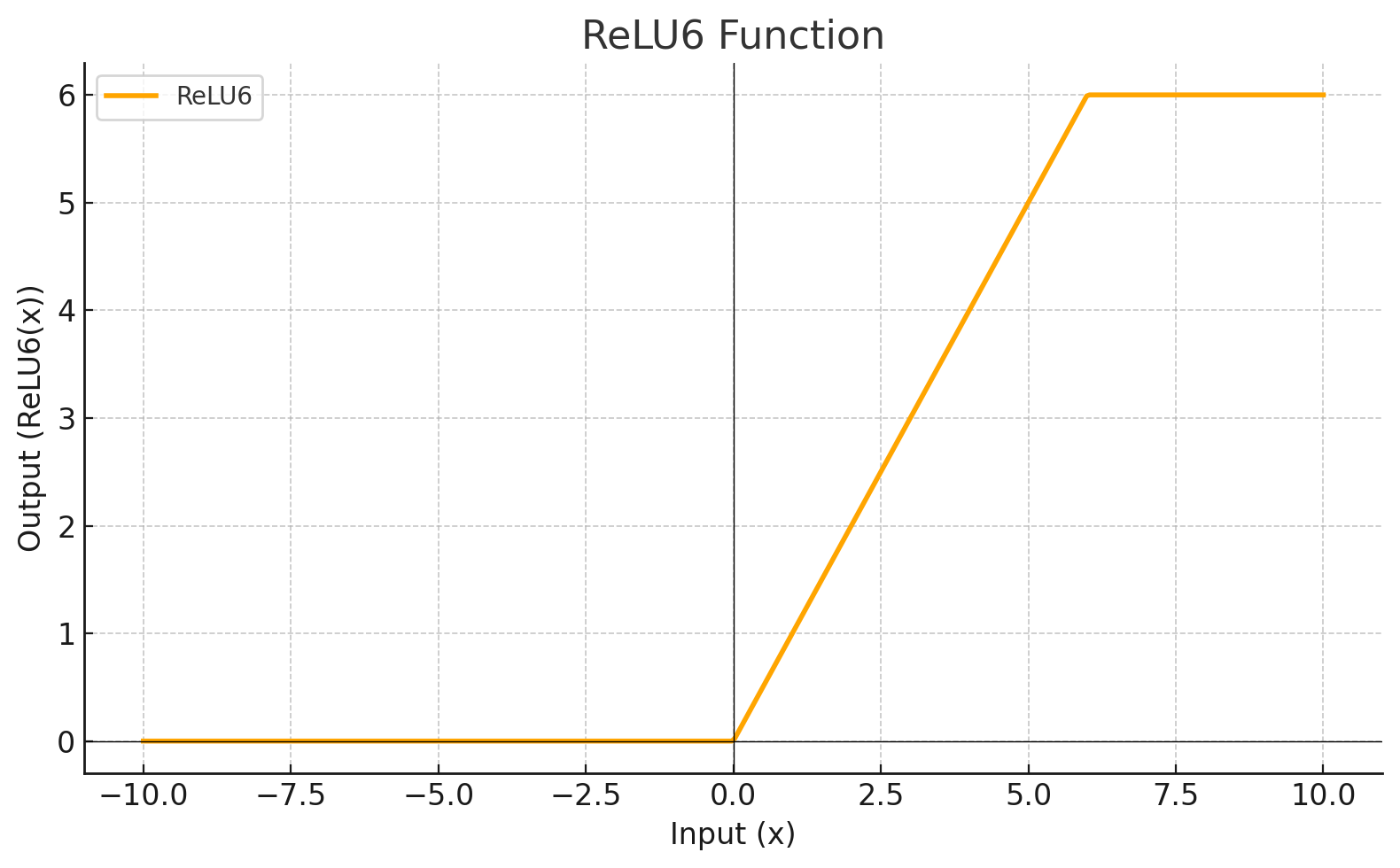
|
| RRELU | 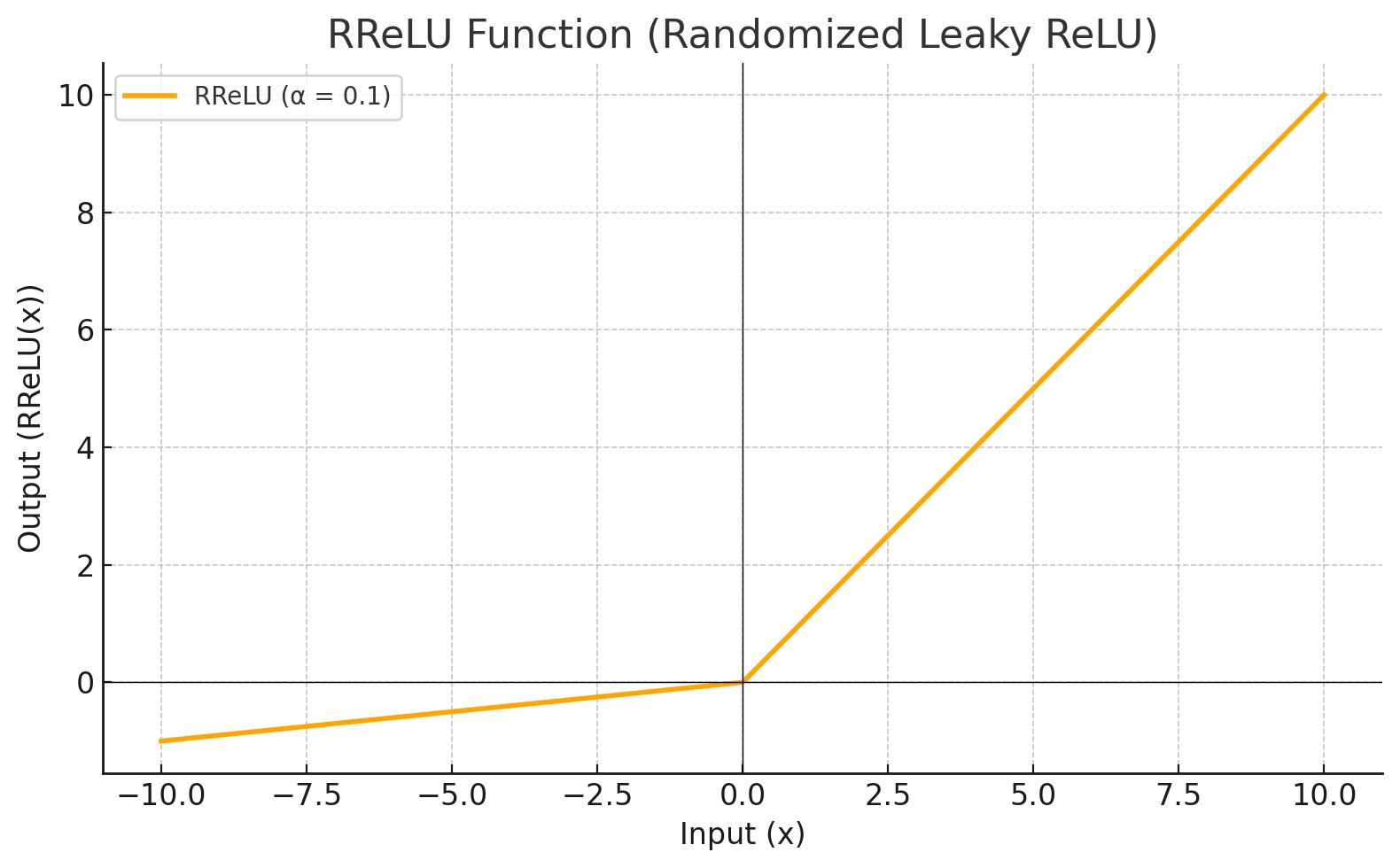
|
| SIGMOID | 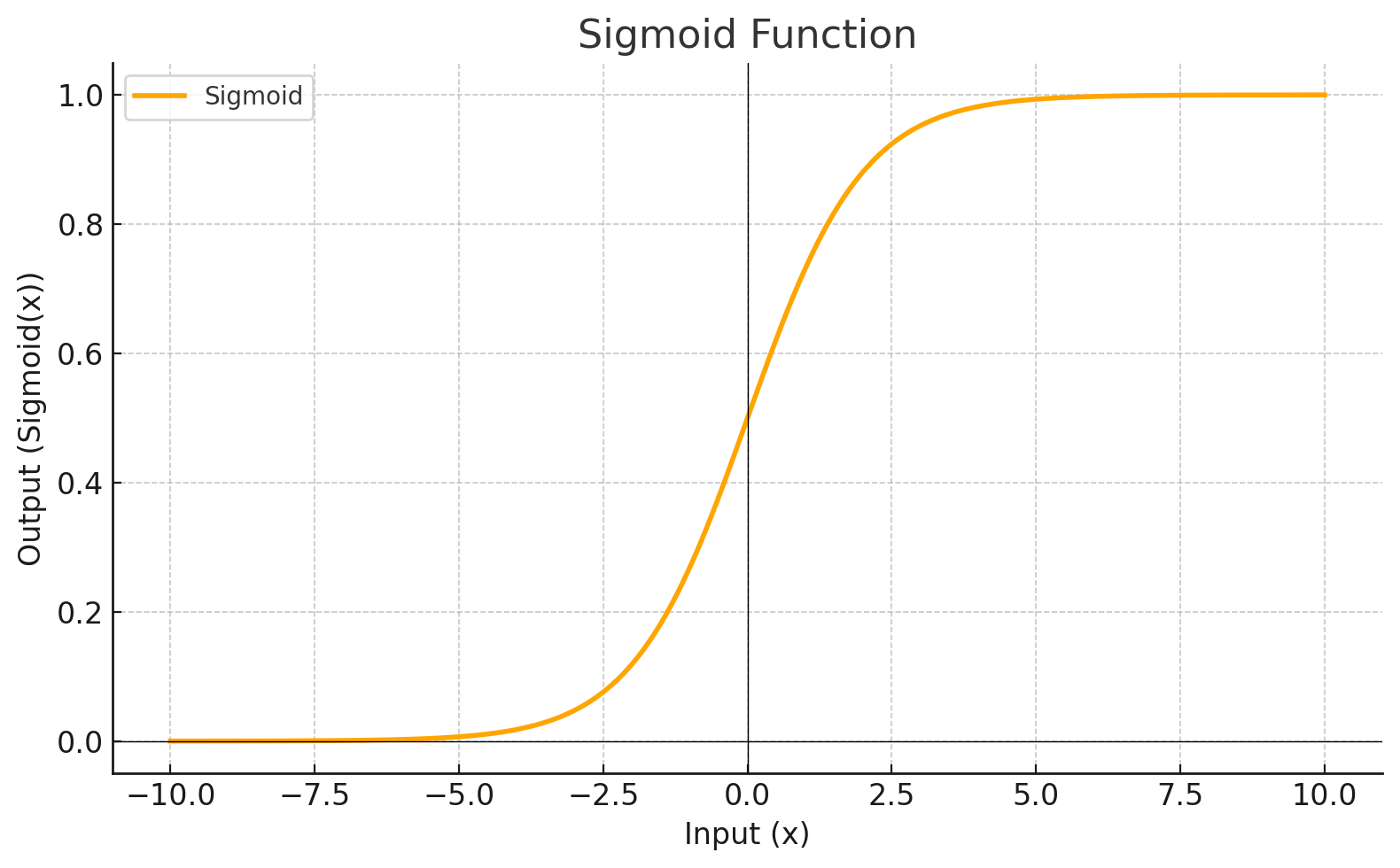
|
| SOFTMAX |
|
| SOFTPLUS | 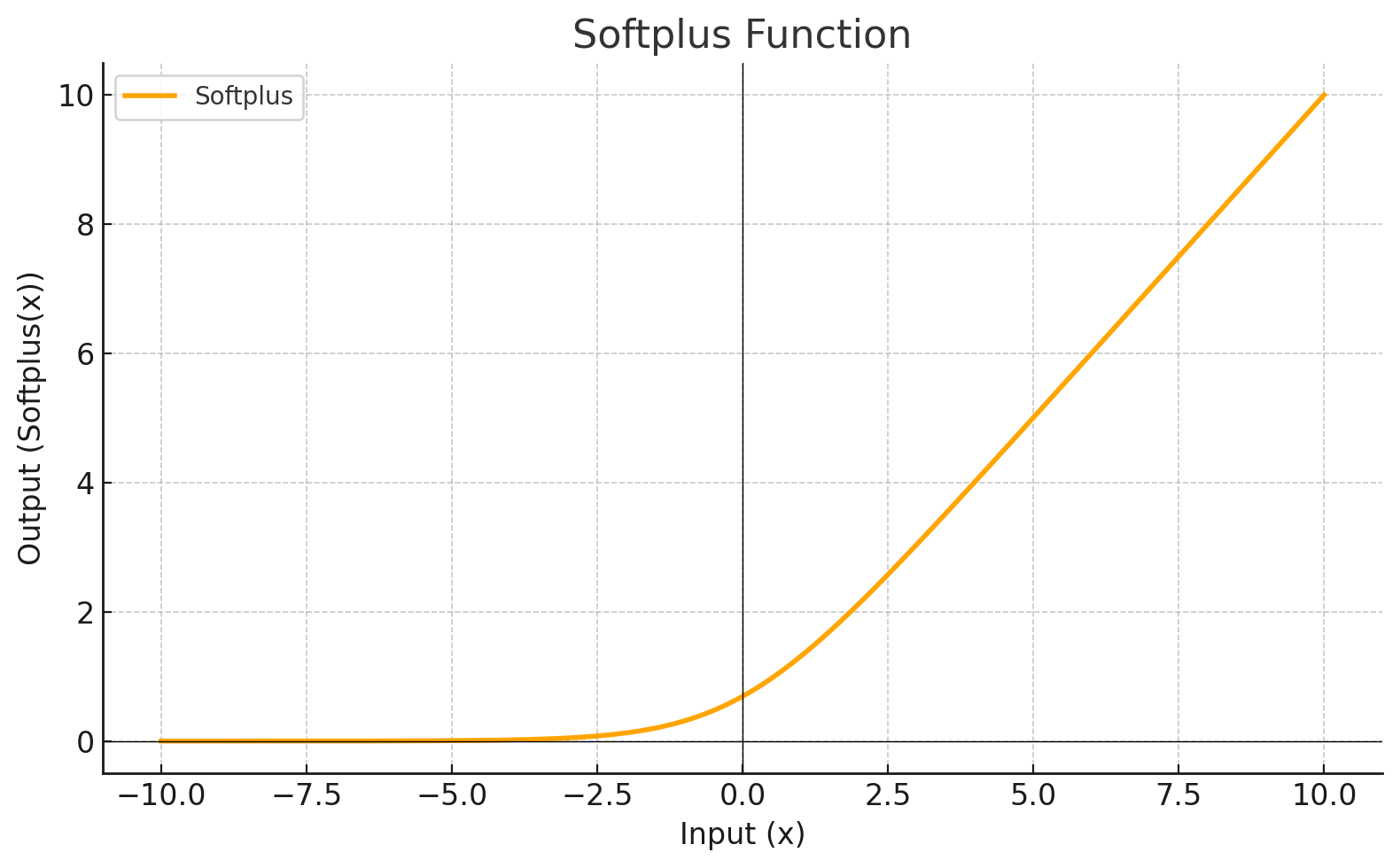
|
| SOFTSIGN | 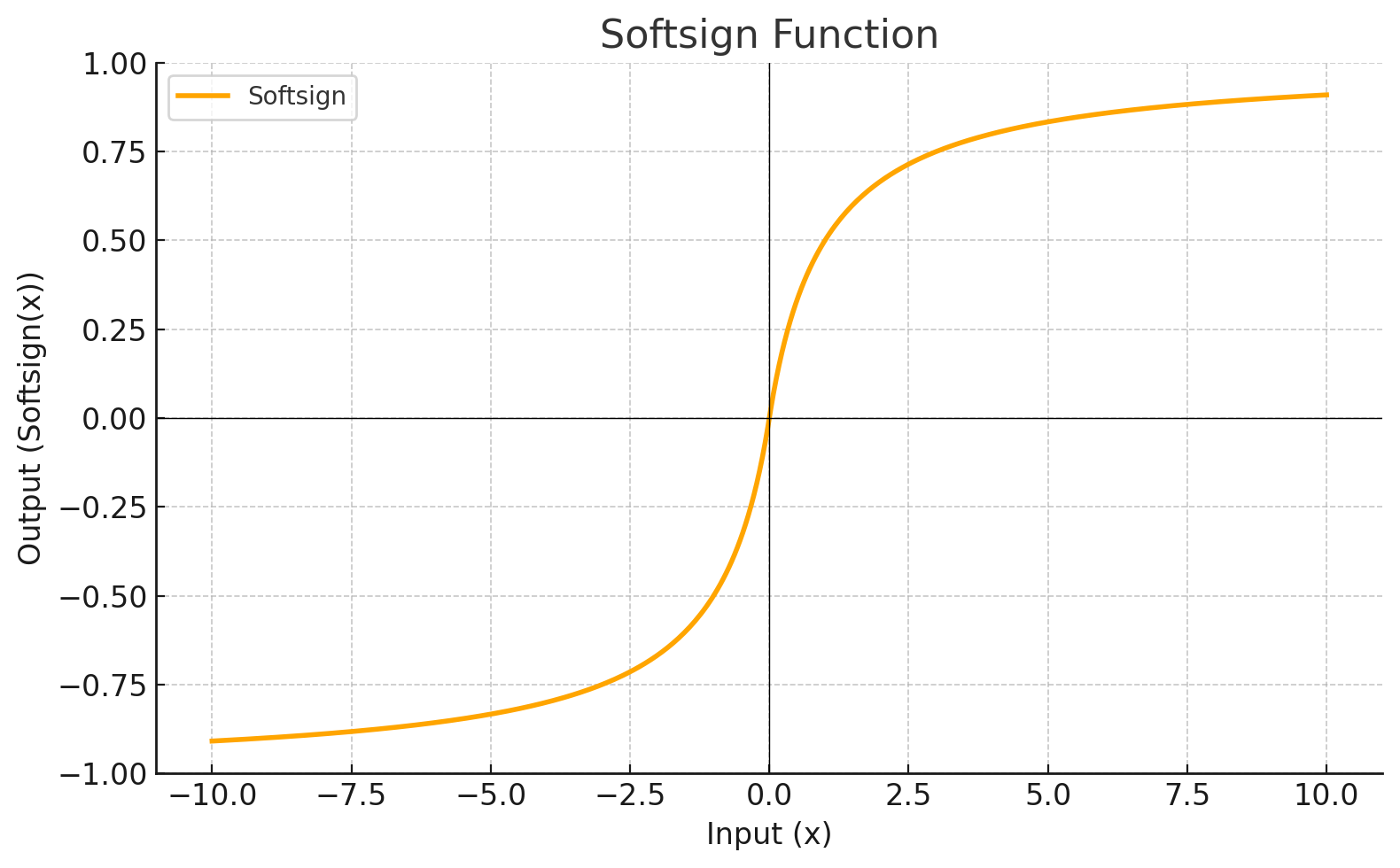
|
| TANH | 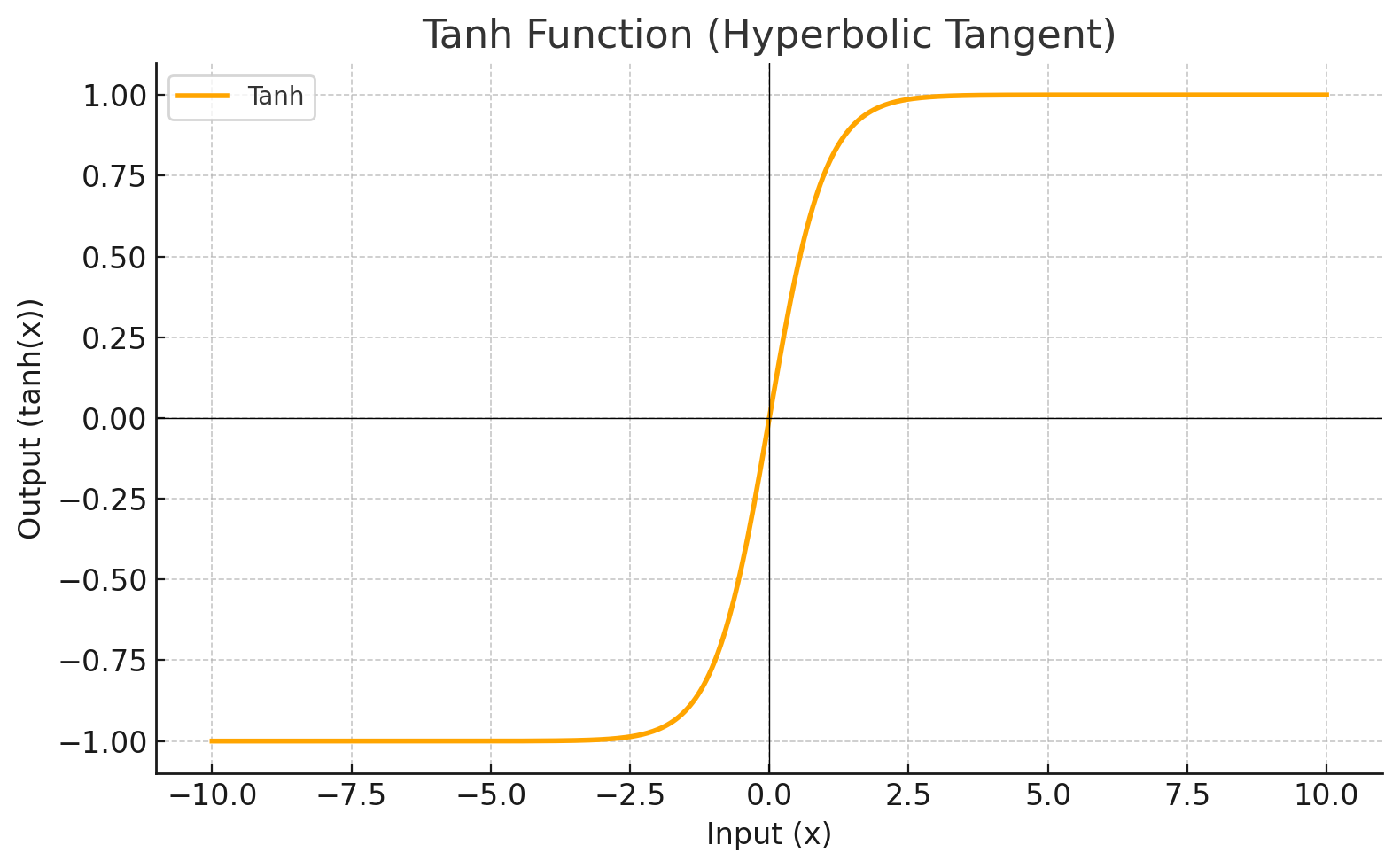
|
| RECTIFIEDTANH | 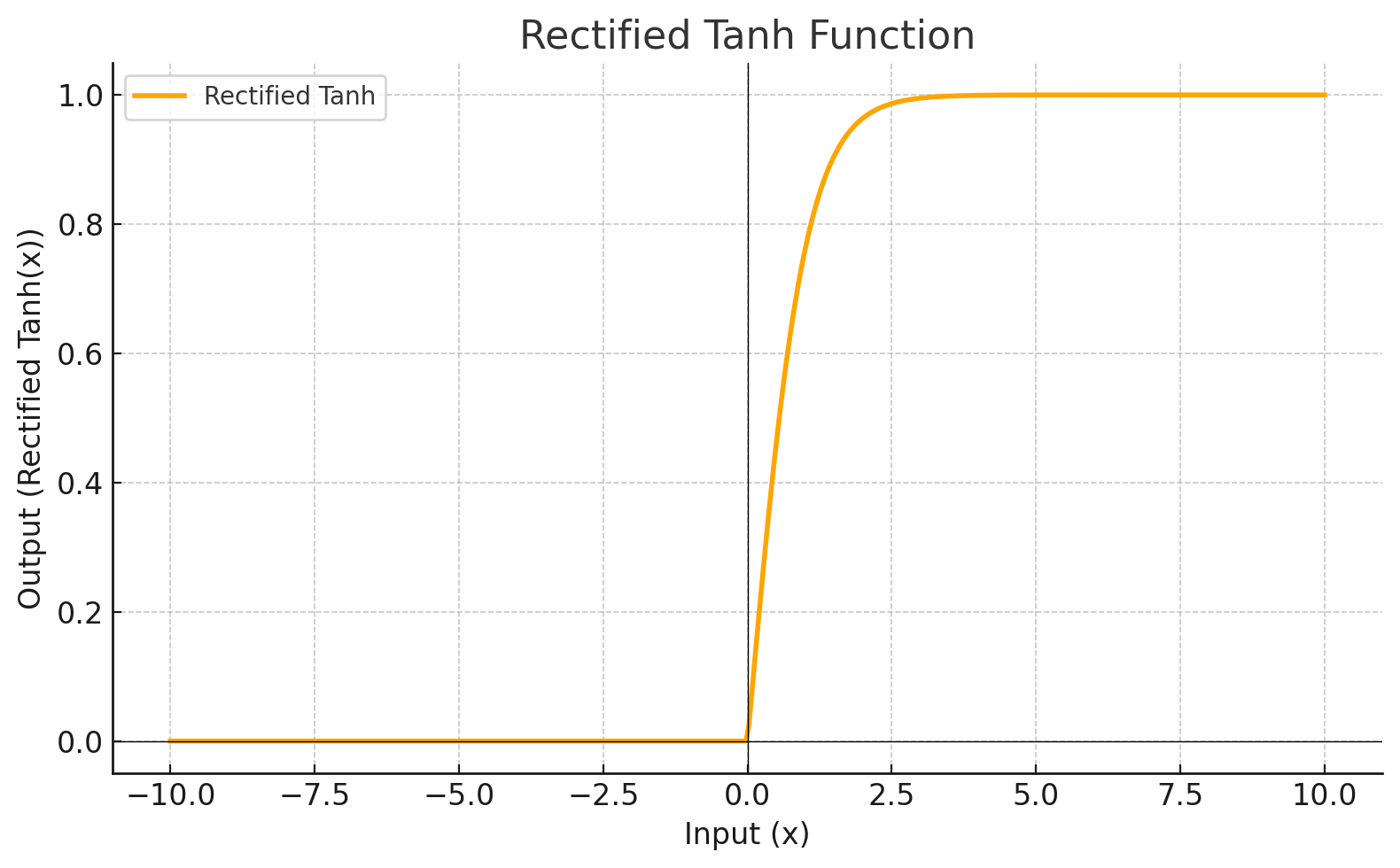
|
| SELU | 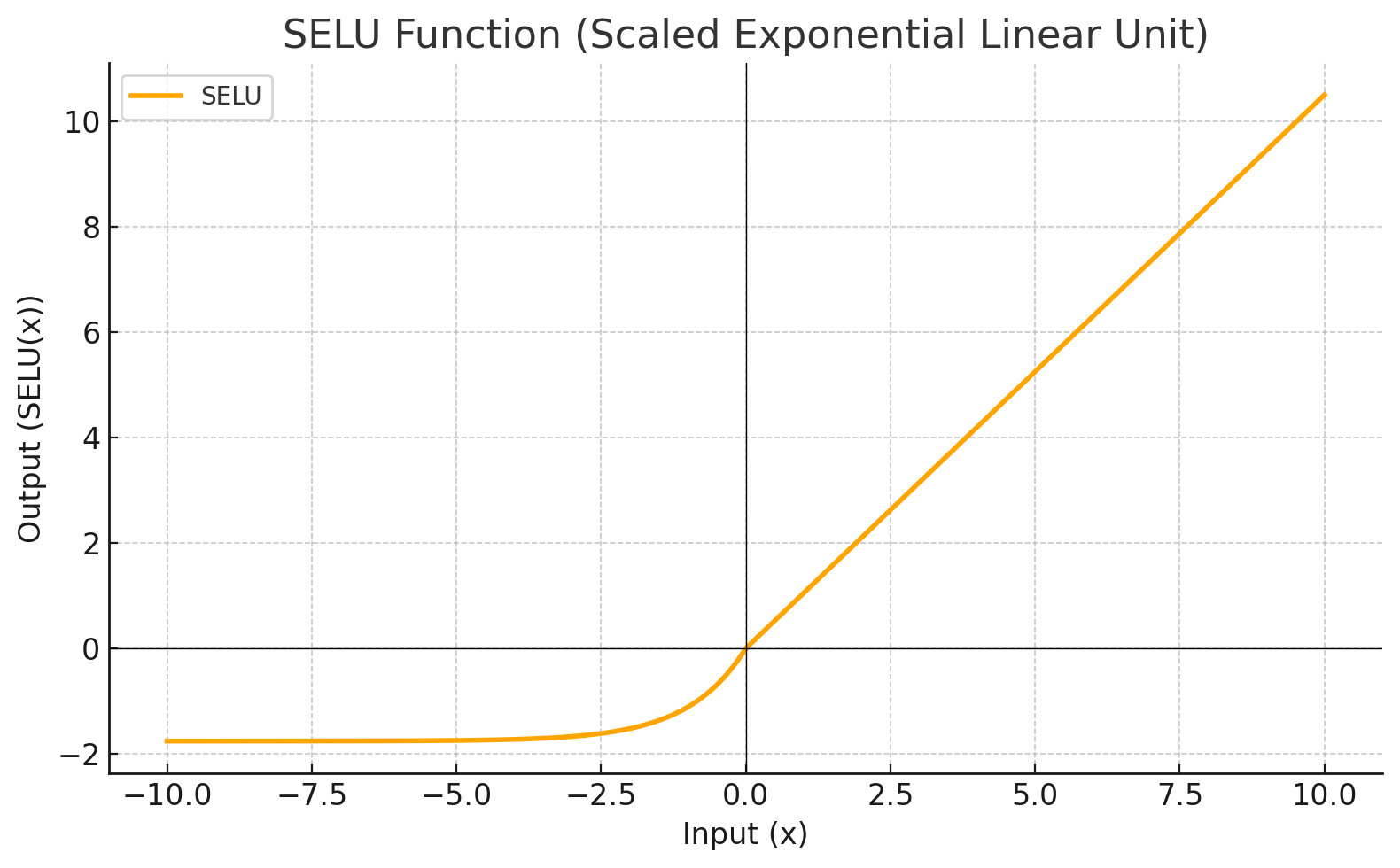
|
| SWISH | 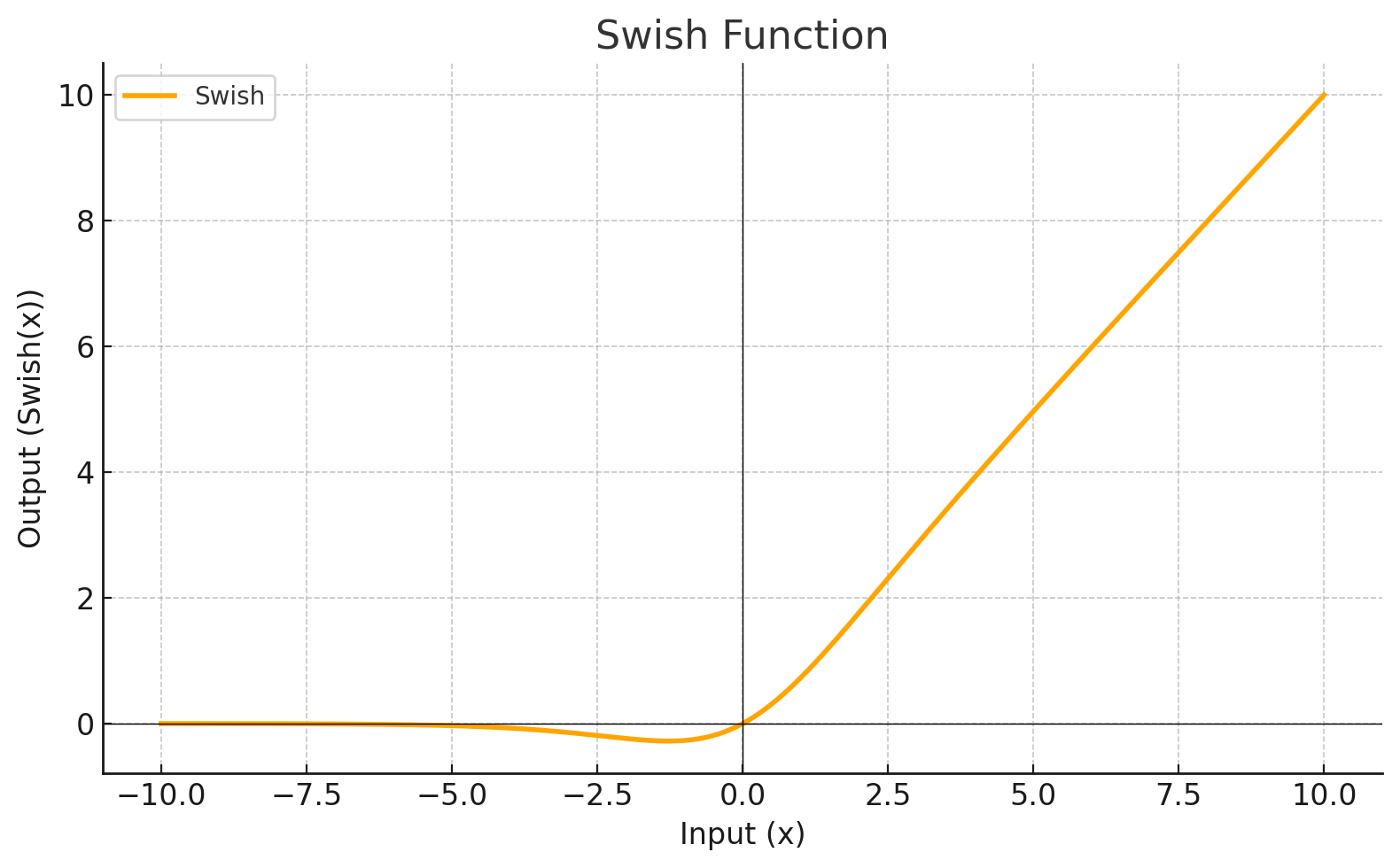
|
| THRESHOLDEDRELU | 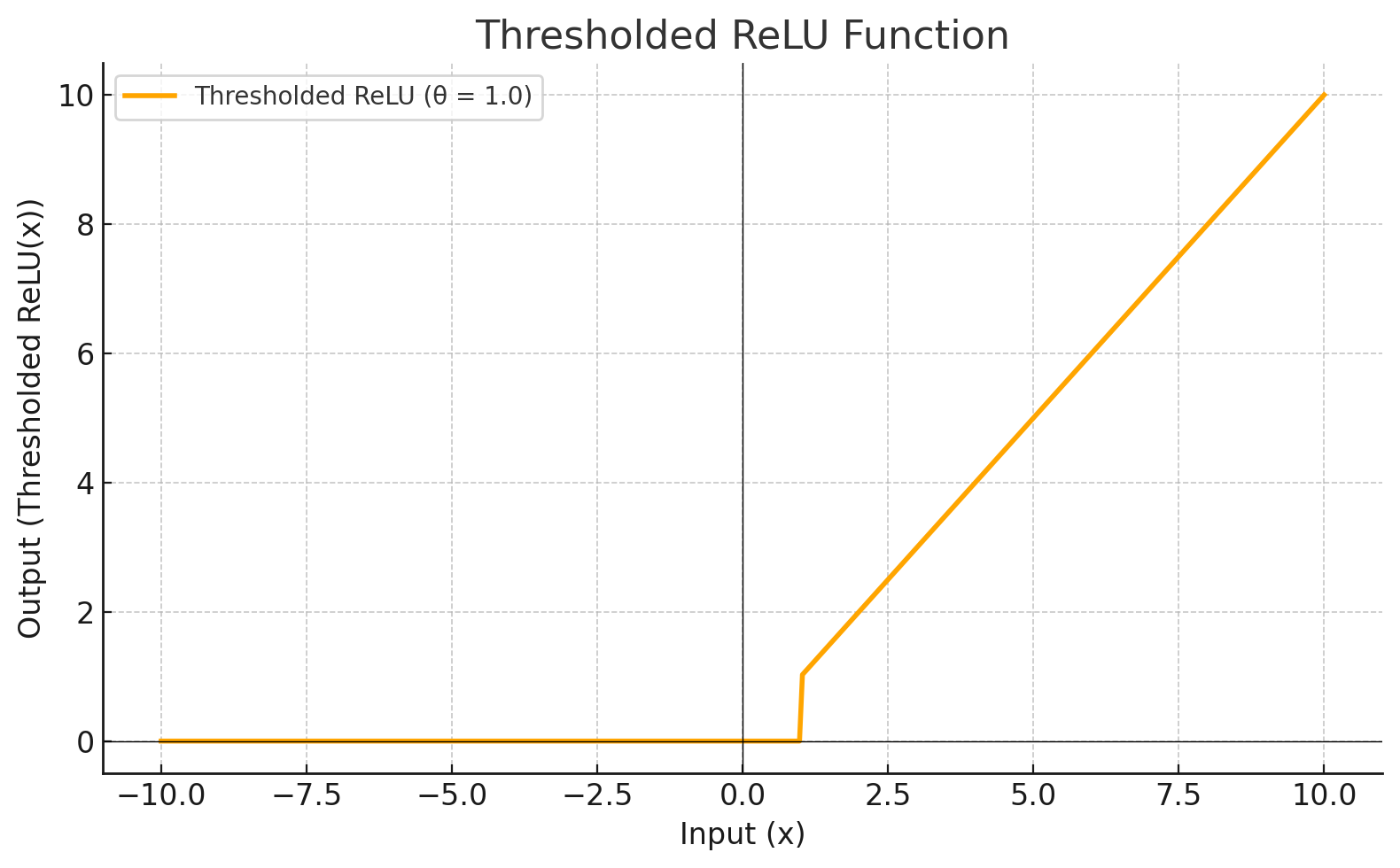
|
| GELU | 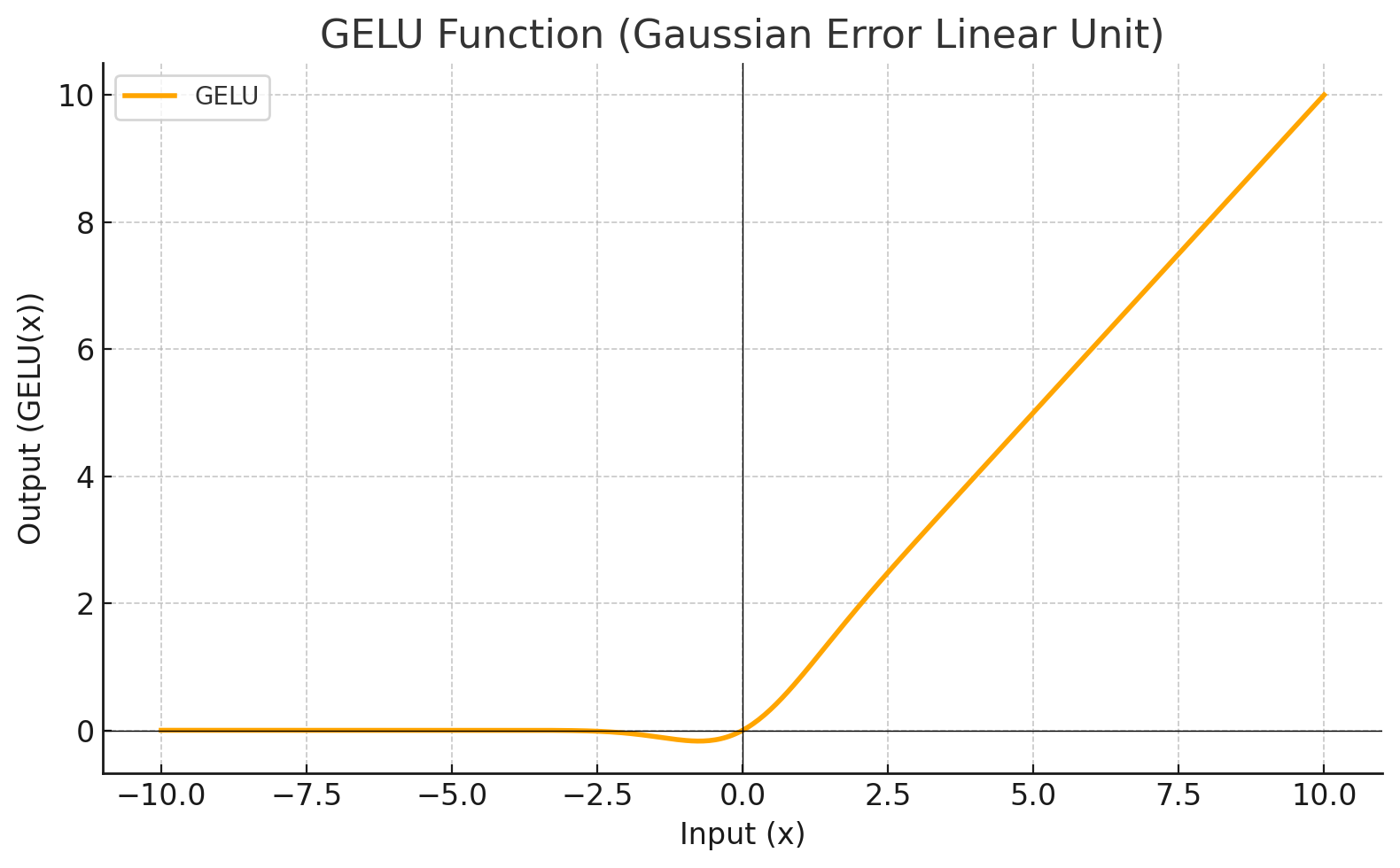
|
| MISH |
|
Capacitación
El entrenamiento de una red neuronal es la tarea de asignar los mejores valores a todos los pesos para minimizar la diferencia entre la predicción del modelo y el valor objetivo real.
Función de Pérdida
Una función de pérdida (también llamada función de coste o función de error) mide la diferencia entre las predicciones de un modelo y los valores objetivo reales. Cuantifica el rendimiento de la red y guía el proceso de aprendizaje al proporcionar una medida numérica del "error". El objetivo durante el entrenamiento es minimizar la función de pérdida, lo que significa que las predicciones del modelo deberían acercarse a los valores reales.
Configuración de una red neuronal
La entrada de una red neuronal es una tupla de números denominada características, por lo que debe especificar el nombre de cada característica en el campo Características como una cadena de nombres separados por comas.
La salida es una de las posibles categorías que se especifican como una cadena de opciones separadas por comas en el campo Categorías.
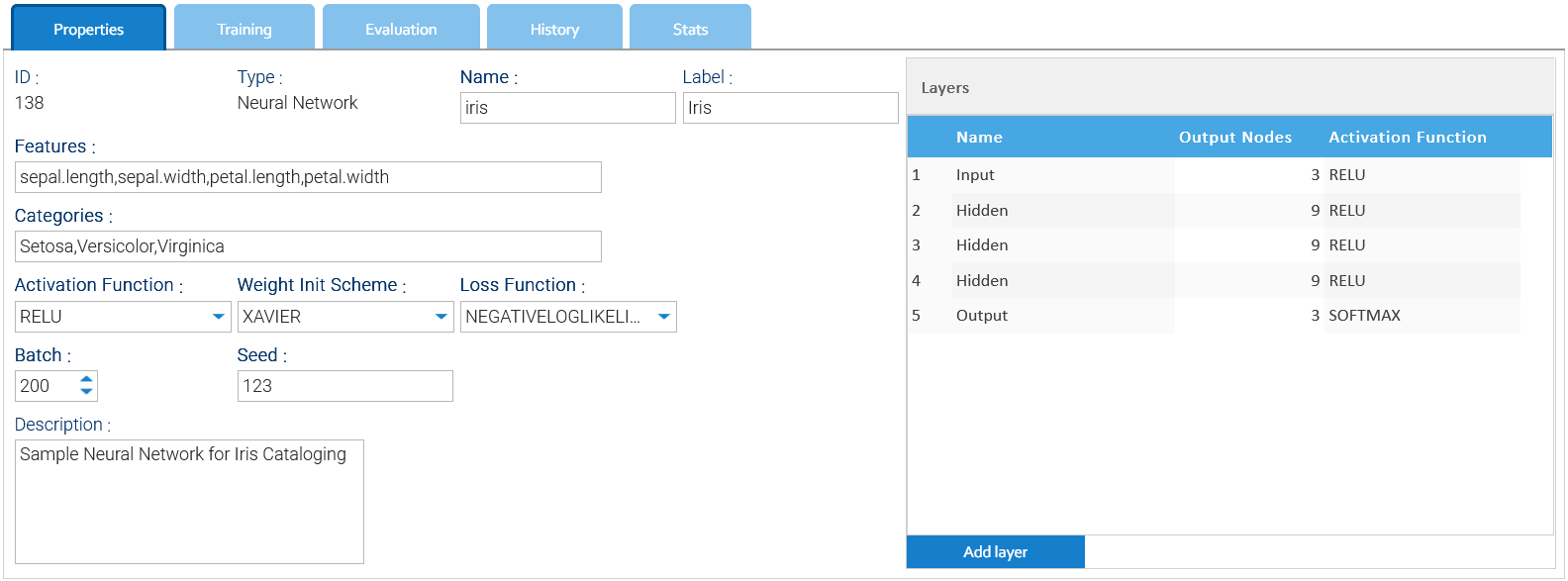
El campo Lote representa el número de muestras devueltas por el iterador de muestras durante el entrenamiento.
Semilla es un número que se utiliza como semilla para el generador interno de números aleatorios.
El Esquema de inicialización de pesos es el algoritmo que se utiliza para asignar un valor inicial a todos los pesos.
En el selector Función de pérdida, se indica la función que se utilizará para medir el error de los valores predichos.
El selector Función de activación indica la función predeterminada que se utilizará para las capas.
En el lado derecho del panel, se definen todas las capas, asignando una función de activación específica para cada una.
Evaluación
La evaluación le permite probar la red contra un subconjunto aleatorio del mismo conjunto de datos de entrenamiento, para iniciar el proceso elija el elemento Comenzar Evaluación del menú contextual y al final mire los resultados en la pestaña Evaluación.
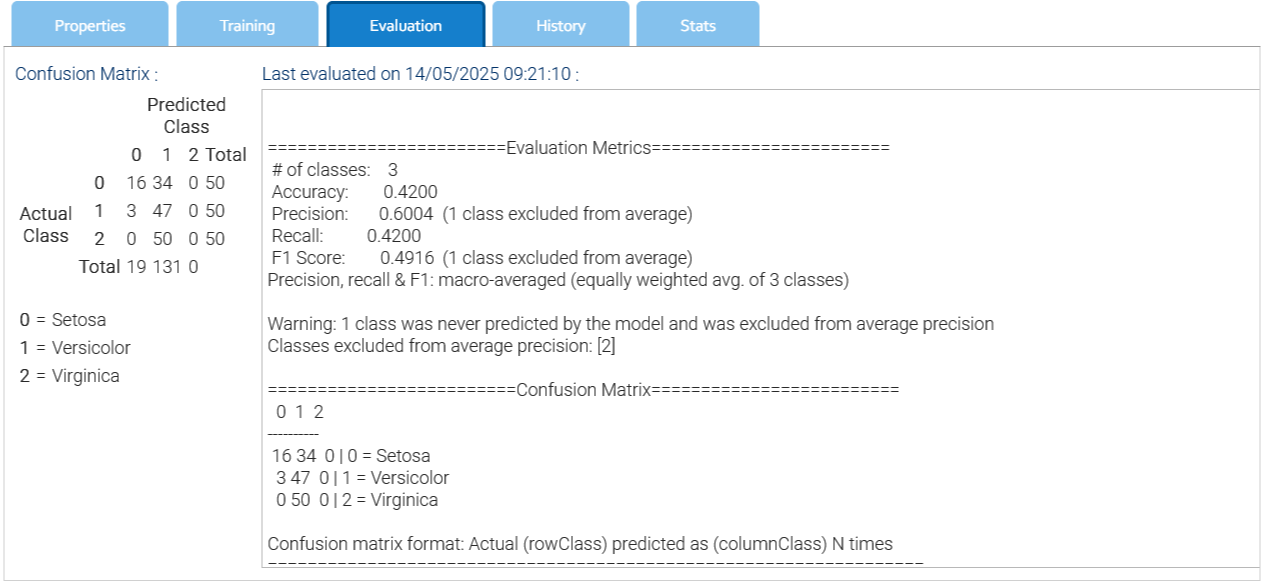
Matriz de confusión
La matriz de confusión es una representación sintética del rendimiento de la red neuronal.
A continuación se muestra un desglose de lo que muestra una matriz de confusión:
Filas: Representan las etiquetas de clase reales (verdaderas) de los datos.
Columnas: Representan las etiquetas de clase predichas por el modelo.
Celdas: Cada celda de la matriz representa una combinación específica de etiquetas reales y predichas. El número en la celda indica cuántas instancias pertenecen a esa categoría.