")
")
")
Language Detector
The Language Detection model automatically identifies the language of a document based on its textual content. This enables the system to classify documents by language and support language-specific processing workflows.
The model is based on a pre-trained implementation provided by Apache OpenNLP and does not require training within the system.
How the Language Detection Model Works
The model analyzes the input text and predicts the most likely language using statistical patterns learned from large multilingual datasets.
Test the Model
To quickly test the model, you can right-click on the model, and select Query the Model, and fill the required fill (Content).
For this example, the content used is:
Ich lehre euch den Übermenschen. Der Mensch ist etwas, das überwunden werden soll. Was habt ihr getan, ihn zu überwinden?
... Alles Wesen bisher schuf etwas über sich hinaus; und ihr wollt die Ebbe dieses grossen Schwindens sein und lieber noch zum Tiere zurückgehen,
als den Menschen überwinden?
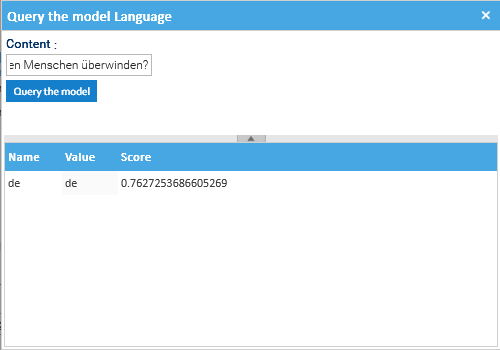
The detected language is returned together with its confidence score.