")
")
")
Búsqueda e indice
Aquí se puede recuperar la información y configurar el motor de búsqueda, los lenguajes de indización, los análizadores disponibles y la cola de documentos para ser indexados.
Motor de búsqueda

Número de entradas: muestra el número de elementos en el índice
Repositorio: la carpeta que almacena el índice
Patrones de Inclusión / Exclusión: los patrones de inclusión / exclusión de nombre de archivo para restringir los documentos que se procesarán
Patrones de Inclusión / Exclusión (solo metadatos): los patrones de inclusión / exclusión de nombre de archivo para restringir los documentos que se procesarán pro con solo los metadatos
Con error, marcar como no indexable: en caso de error, el documento se marca como no indexable
Ordenamiento: define el orden utilizado para procesar los documentos
Lote: número de documentos procesados en cada indexación
Tiempo de espera por ánalisis: máx. tiempo para procesar un documento
Texto max: número máximo de caracteres a almacenar en el índice al analizar un archivo
Tamaño máximo archivo de texto: amaño máximo analizado para archivos de texto, expresado en KB
Guardar: se confirmarán todos los cambios
Desbloquear: el índice de texto completo será desbloqueado
Limpiar: elimina del índice aquellas entradas que hacen referencia a archivos eliminados
Reprogramar todo para la indexación: todos los documentos se reprograman para la indexación de nuevo
Quitar indice: borra el índice actual
Verificar: se mostrará un informe sobre el estado de texto Índice
Filtros
La forma en que tus textos se procesan durante la indexación depende de los filtros. Los filtros examinan una cadena de fichas de texto, las mantienen, transforman o descartan, o crean otras nuevas fichas. Los filtros pueden ser combinados en cadenas, donde la salida de uno es la entrada al siguiente. Tal secuencia de filtros se utiliza para elaborar los resultados de una búsqueda y para construir el índice. En la ficha Filtros se ve la lista de filtros disponibles, por supuesto, puede cambiar su orden y desactivar / activar ellos.

Si expande un filtro también puede configurar sus parametros específicos, aquí una breve descripción de los filtros disponibles:
Filtro: stemmer
Utiliza el lenguaje del documento para contener las palabras.
Ejemplo: "Take papers everywhere" produce: "take", "paper", "every"
Filtro: worddelimiter
Divide fichas en delimitadores de palabra. Las reglas para delimitadores que determinan se determinan como sigue:
- Un cambio en el caso dentro de una palabra: "CamelCase" -> "Camel", "Case". Esto se puede desactivar mediante el parametro splitOnCaseChange="0".
- Una transición de caracteres alfa a numéricos o viceversa: "Gonzo5000" -> "Gonzo", "5000" "4500XL" -> "4500", "XL". Esto se puede desactivar mediante el parametro splitOnNumerics="0".
- Los caracteres no alfanuméricos(descartados): "hot-spot" -> "hot", "spot"
- Un arrastre "'s" se retira: "O'Reilly's" -> "O", "Reilly"
- Cualquier delimitadores iniciales o finales se descartan: "--hot-spot--" -> "hot", "spot"
| Configuraciones | |
|---|---|
| types | el archivo de configuración que define los tipos de caracteres, la ruta es relativa a <LDOC_HOME>/repository/index/logicaldoc/conf |
| generateWordParts | (integer, default 1) If non-zero, splits words at delimiters. For example:"CamelCase", "hot-spot" -> "Camel", "Case", "hot", "spot" |
| generateNumberParts | (integer, default 1) If non-zero, splits numeric strings at delimiters:"1947-32" ->"1947", "32" |
| splitOnCaseChange | (integer, default 1) If 0, words are not split on camel-case changes:"BugBlaster-XL" -> "BugBlaster", "XL". Example 1 below illustrates the default (non-zero) splitting behavior. |
| splitOnNumerics | (integer, default 1) If 0, don't split words on transitions from alpha to numeric:"FemBot3000" -> "Fem", "Bot3000" |
| catenateWords | (integer, default 0) If non-zero, maximal runs of word parts will be joined: "hot-spot-sensor's" -> "hotspotsensor" |
| catenateNumbers | (integer, default 0) If non-zero, maximal runs of number parts will be joined: 1947-32" -> "194732" |
| catenateAll | (0/1, default 0) If non-zero, runs of word and number parts will be joined: "Zap-Master-9000" -> "ZapMaster9000" |
| preserveOriginal | (integer, default 0) If non-zero, the original token is preserved: "Zap-Master-9000" -> "Zap-Master-9000", "Zap", "Master", "9000" |
| stemEnglishPossessive | (integer, default 1) If 1, strips the possessive "'s" from each subword |
Filtro: ngram
Genera fichas n-gram de tamaños en el intervalo dado. Toma nota de que las fichas están clasificadas por posición y luego por tamaño.
Ejemplo: "four score" produce: "f", "o", "u", "r", "fo", "ou", "ur", "s", "c", "o", "r", "e", "sc", "co", "or", "re"
| Configuraciones | |
|---|---|
| minGramSize | (integer, default 1) The minimum gram size |
| maxGramSize | (integer, default 2) The maximum gram size |
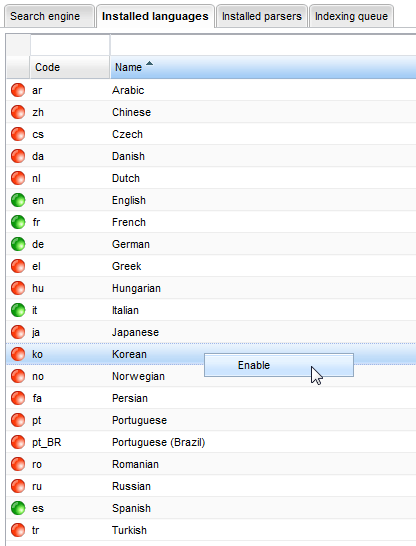
Idiomas
En este panel se puede ver todos los idiomas del sistema disponibles. Puede activar o desactivar cada una de ellas haciendo clic derecho en el elemento y seleccione la opción Activar o Desactivar.
Analizadores
En este panel se puede ver todos los analizadores del sistema.

Historial
En este panel, están los eventos de indexación. Aquí puedes ver aciertos y errores:

Cola de la indexación
En este panel se puede ver todos los documentos no indexados ya. Usted puede sacar de la indexación un documento haciendo clic derecho sobre el elemento y luego seleccionar Marcar como no indexable.

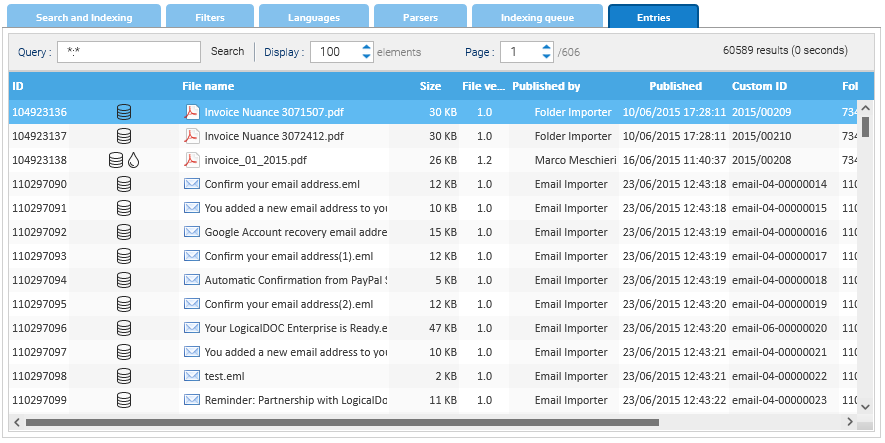
Entradas
En este panel puede realizar búsquedas de bajo nivel para inspeccionar las entradas contenidas en el índice de texto completo.