")
")
")
High Availability and Disaster Recovery
The High Availability (HA) architecture is the right option when the document management becomes business-critical and requires minimal downtime and continuous availability.
The same architecture is also used to implement a Disaster Recovery (DR) where the purpose is to guarantee the survival of the service even in the face of a serious event on the main node.
In both cases, the solution is to use two nodes: the main one which is normally used to serve the traffic and the secondary one to which requests are delegated only if the main node is out of service.
For the HA both nodes are in the same LAN, while for the DR they are located in distinct geographic areas.
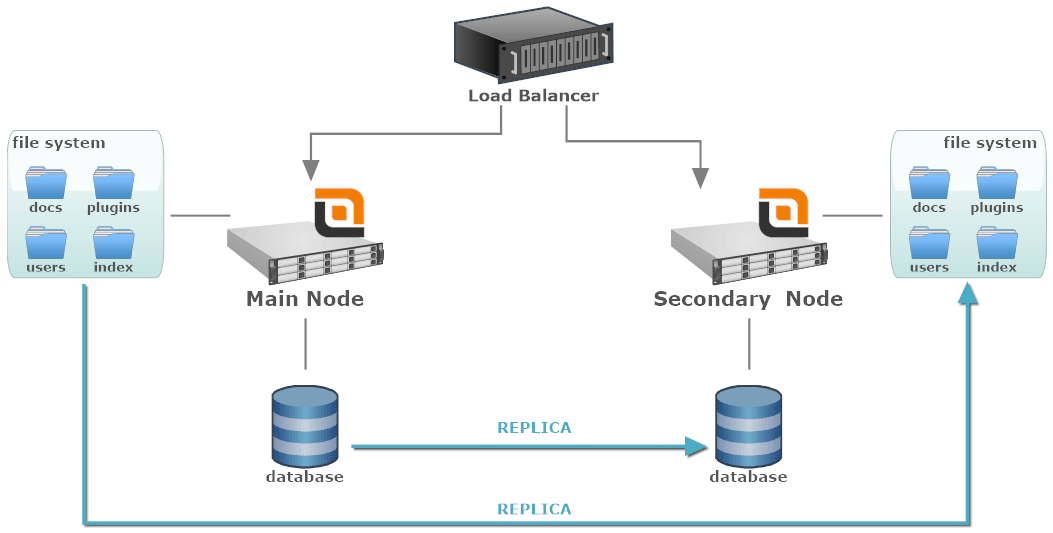
- Load Balancer:a software or hardware component that identifies when the main node is down and routes the incoming traffic to the secondary node.
- Main Node: the active instance that normally receives the traffic. It can be a single node or in turn a Best Performance cluster.
- Secondary Node: the standby instance that will receive the traffic when the main node is unavailable.
- Local File System: the file system attached to a specific node. It could be a local drive or whatever other storage device not shared among other nodes of the cluster.
- Database Server: the database is shared among all the nodes. It could be a single node or another cluster of database servers.
Each node has its own storage and database, but both are continuously replicated from the main node to the secondary one. In this way as soon as the main node becomes unavailable, the system will continue to work thanks to the secondary one that starts with the data from the last replication.
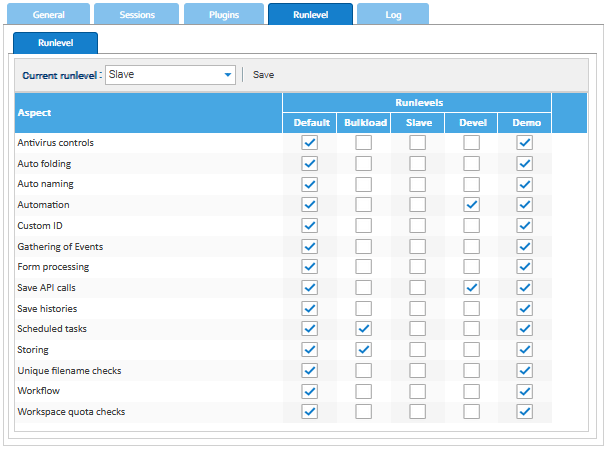
Set up the run level
Because of in this approach there is no communication between both applications, there is no need to activate the clustering feature.
The main node should be configured to work in Default run level as usual, while the secondary should work in the Slave run level. By default, most of the aspects are disabled in the slave, a good solution for a consultation only system. If you want a fully functional system, you may switch to the Default run level as soon as the secondary node takes the control.
Replication policies
The two metrics normally used to evaluate HA (and also Disaster Recovery (DR)) are the Recovery Time Objective (RTO) and the Recovery Point Objective (RPO).
- RTO is the maximum tolerable duration of any outage.
- RPO is the maximum amount of data loss that can be tolerated when an error occurs.
There is a difference between RTOs and RPOs that can be obtained to support high availability versus disaster recovery. With HA, data replication can be synchronous because the redundant components are located in the LAN environment. Active and standby databases can be updated at the same time, enabling full, automatic and real-time recoveries to satisfy the most demanding RTOs and RPOs. As a result, the standby instance is "hot" and in sync with the active instance, so it is ready to take over immediately in the event of a failure.
However, to recover systems, software, and data in the event of a disaster, the redundant components must be on a wide area network (WAN). This is important because you need to keep the redundant components in a geographic location away from the active instance. But with a WAN, data replication is asynchronous to avoid a negative impact on throughput performance. This means that updates to standby instances will delay updates made to the active instance, causing a delay during the restore process. Since disasters are rare, some delay can be tolerable and depends on (a) how critical it is for your business to achieve the lowest possible RTO and RPO and (b) how much budget you can allocate to achieve the best RTO and RPO.
Depending on the RTO and RPO you want to reach, you should regulate how frequent is the replication of the data from the main node to the secondary one.