")
")
")
Ricerca e indicizzazione
Qui è possibile recuperare informazioni e configurare il motore di ricerca, le lingue installate, i parser disponibili e la coda di documenti da indicizzare.
Motore di ricerca

Conteggio elementi: visualizza il numero di elementi nell'indice
Repository: la cartella che memorizza l'indice
Filtri di Inclusione / Esclusione: schemi di inclusione / esclusione sul nome file per limitare i documenti da processare
Filtri di Inclusione / Esclusione (solo metadati): schemi di inclusione / esclusione sul nome file per limitare i documenti da processare con solo i metadati
Con errore, contrassegna come non indicizzabile: In caso di errore, il documento viene contrassegnato come non indicizzabile
Ordinamento: definisce l'ordine utilizzato per elaborare i documenti
Batch: numero di documenti elaborati ad ogni indicizzazione
Timeout nel Parsing: massimo tempo per elaborare un unico documento
Testo massimo: numero massimo di caratteri salvati nell'indice per ogni singolo documento
Dim. massima file testo: massima dimensione analizzata per i file di testo, espressa in KB
Salva: saranno memorizzate tutte le modifiche
Sblocca: l'indice full-text sarà sbloccato
Pulisci: rimuove dall'indice quelle voci che fanno riferimento a file eliminati
Marca tutti per l'indicizzazione: tutti i documenti vengono riprogrammati per essere indicizzati di nuovo
Elimina indice: cancella l'indice attuale
Verifica: sarà mostrato un rapporto sullo stato indice full-text
Filtri
Il modo in cui i testi vengono elaborati durante l'indicizzazione dipende dai filtri. I filtri esaminano un flusso di frammenti di testo e possono conservarli, trasformarli o scartarli, o crearne di nuovi. I filtri possono essere combinati in una catena, in cui l'uscita di uno è l'ingresso per il successivo. Tale sequenza di filtri viene utilizzata per comporre i risultati delle ricerche e per costruire l'indice. Nella scheda Filtri si vede l'elenco di tutti i filtri disponibili, naturalmente si possono riordinare e disabilitare / abilitare.

Se si espande un filtro è anche possibile configurare i suoi parametri specifici, ecco una breve descrizione dei filtri disponibili:
Filtro: stemmer
Usa un linguaggio del documento per separare le radici delle parole:
Esempio: "Take papers everywhere" produce: "take", "paper", "every"
Filtro: worddelimiter
Divide i frammenti con delimitatori di parola. Le regole per le delimitazioni sono impostate come segue:
- Cambiamento di caso all'interno della parola: "CamelCase" -> "Camel", "Case". Può essere disabilitato con il parametro splitOnCaseChange="0".
- Una transizione da alfa a caratteri numerici o viceversa: "Gonzo5000" -> "Gonzo", "5000" "4500XL" -> "4500", "XL". Può essere disabilitato con il parametro splitOnNumerics="0".
- Caratteri non alfanumerici(scartato): "hot-spot" -> "hot", "spot"
- Un finale "'s" viene rimosso: "O'Reilly's" -> "O", "Reilly"
- Eventuali delimitatori iniziali o finali vengono scartati: "--hot-spot--" -> "hot", "spot"
| Configurazione | |
|---|---|
| types | il file di configurazione che definisce i tipi di caratteri, il percorso è relativo a <LDOC_HOME>/repository/index/logicaldoc/conf |
| generateWordParts | (integer, default 1) If non-zero, splits words at delimiters. For example:"CamelCase", "hot-spot" -> "Camel", "Case", "hot", "spot" |
| generateNumberParts | (integer, default 1) If non-zero, splits numeric strings at delimiters:"1947-32" ->"1947", "32" |
| splitOnCaseChange | (integer, default 1) If 0, words are not split on camel-case changes:"BugBlaster-XL" -> "BugBlaster", "XL". Example 1 below illustrates the default (non-zero) splitting behavior. |
| splitOnNumerics | (integer, default 1) If 0, don't split words on transitions from alpha to numeric:"FemBot3000" -> "Fem", "Bot3000" |
| catenateWords | (integer, default 0) If non-zero, maximal runs of word parts will be joined: "hot-spot-sensor's" -> "hotspotsensor" |
| catenateNumbers | (integer, default 0) If non-zero, maximal runs of number parts will be joined: 1947-32" -> "194732" |
| catenateAll | (0/1, default 0) If non-zero, runs of word and number parts will be joined: "Zap-Master-9000" -> "ZapMaster9000" |
| preserveOriginal | (integer, default 0) If non-zero, the original token is preserved: "Zap-Master-9000" -> "Zap-Master-9000", "Zap", "Master", "9000" |
| stemEnglishPossessive | (integer, default 1) If 1, strips the possessive "'s" from each subword |
Filtro: ngram
Generara iframmenti n-gram di dimensioni nel range indicato. Si noti che i frammenti sono ordinati per posizione e poi in base alle dimensioni.
Esempio: "four score" produce: "f", "o", "u", "r", "fo", "ou", "ur", "s", "c", "o", "r", "e", "sc", "co", "or", "re"
| Configurations | |
|---|---|
| minGramSize | (integer, default 1) The minimum gram size |
| maxGramSize | (integer, default 2) The maximum gram size |
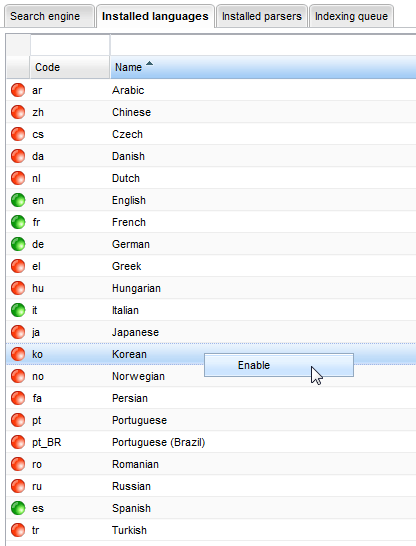
Lingue
In questo pannello è possibile vedere tutte le lingue disponibili. È possibile abilitare o disabilitare ciascuna di esse, cliccando sulla voce e selezionando l'opzione Attiva o Disattiva.
Analizzatori
In questo pannello è possibile vedere tutti gli analizzatori del sistema.

Cronologia
In questo pannello ci sono gli eventi di indicizzazione. Qui puoi vedere i successi e gli errori:

Coda di indicizzazione
In questo pannello è possibile visualizzare tutti i documenti ancora da indicizzare. È possibile togliere dall'indicizzazione un documento facendo clic destro sulla voce e selezionando l'opzione Marca come non indicizzabile.

Elementi
In questo pannello è possibile effettuare ricerche di basso livello per ispezionare le voci contenute nell'indice full-text