")
")
")
Mejor Rendimiento
El propósito de este tipo de clustering es aumentar el rendimiento cuando las mejoras en un solo servidor no serían suficientes. Un escenario típico es cuando tiene muchos usuarios simultáneos o un repositorio de documentos muy grande para indexar.
LogicalDOC admite el clustering para maximizar el rendimiento, distribuyendo las cargas de CPU y RAM entre un conjunto de nodos llamado clúster. La mayor parte del estrés en una instalación grande se debe a las operaciones de análisis, indexación y búsqueda. Por esta razón, cada nodo LogicalDOC manejará su propio índice de texto completo y una búsqueda federada abarcará todos los nodos.
Debe configurar al menos dos instancias distintas de LogicalDOC ejecutándose en la misma red en diferentes nodos. También debe colocar un equilibrador de carga hardware frente al clúster para distribuir las solicitudes de manera uniforme.
Implementación con un file system local
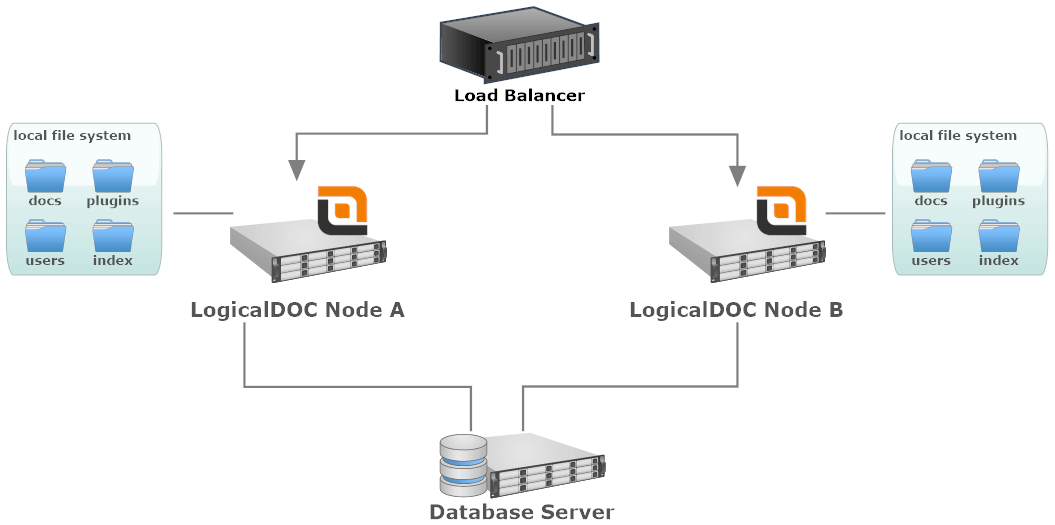
- Load Balancer: un componente software o hardware que distribuye uniformemente el tráfico entrante a los nodos del clúster.
- LogicalDOC Node: cada nodo es una instancia única de LogicalDOC instalada en un servidor dedicado. Puede utilizar servidores físicos o virtuales.
- Local File System: el sistema de archivos adjunto a un nodo específico. Podría ser una unidad local o cualquier otro dispositivo de almacenamiento que no se comparta entre otros nodos del clúster.
- Database Server: la base de datos se comparte entre todos los nodos. Podría ser un solo nodo u otro grupo de servidores de bases de datos.
En este diseño, la mayoría de los recursos, como los repositorios de documentos, son completamente locales, por lo que sus documentos se almacenarán físicamente entre los diferentes nodos. Cuando un nodo requiere un documento o cualquier otro recurso que no encuentra localmente, se comunicará con los otros nodos para obtenerlo. Al mismo tiempo, cada nodo mantiene un índice parcial de texto completo, por lo que en el momento de la búsqueda, todos los demás nodos serán contactados para recopilar los resultados indexados en otro lugar (es decir, una búsqueda federada).
Advertencia
Debido a que en este escenario, los documentos se almacenan entre diferentes nodos, se podría generar mucho tráfico en su LAN cuando se transfieran de un nodo a otro. Por lo que se sugiere activar la opción Cache en la configuración del clustering de cada nodo.
Implementación con un file system compartido
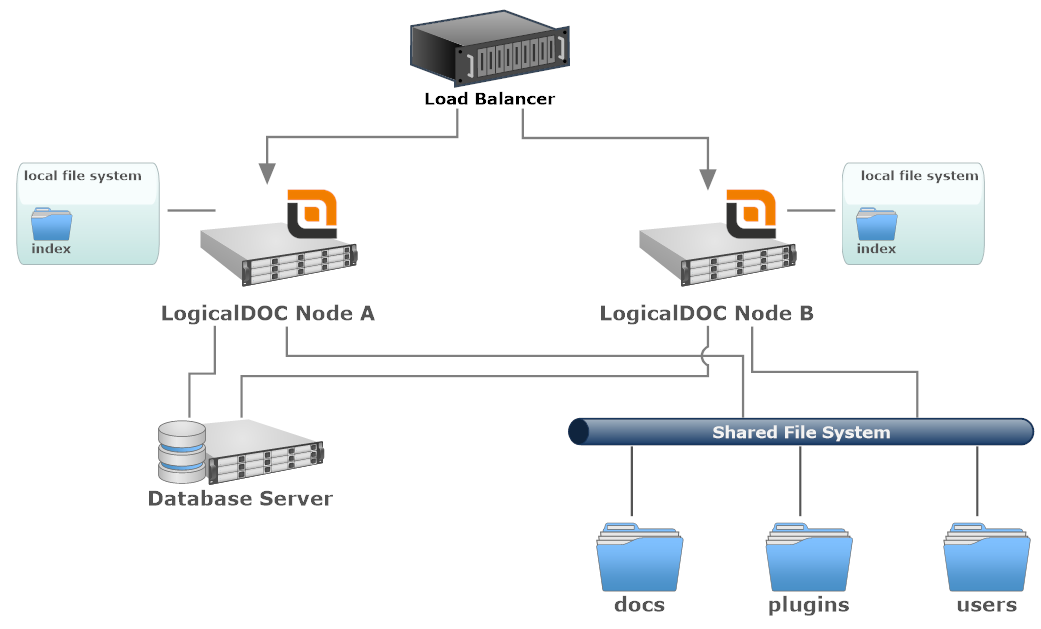
- Load Balancer: un componente software o hardware que distribuye uniformemente el tráfico entrante a los nodos del clúster.
- LogicalDOC Node: cada nodo es una instancia única de LogicalDOC instalada en un servidor dedicado. Puede utilizar servidores físicos o virtuales.
- Local File System: el sistema de archivos adjunto a un nodo específico. Podría ser una unidad local o cualquier otro dispositivo de almacenamiento que no se comparta entre otros nodos del clúster.
- Shared File System: un sistema de archivos compartidos común a todos los nodos. Puede usar varios volúmenes y/o NAS dedicado.
- Database Server: la base de datos se comparte entre todos los nodos. Podría ser un solo nodo u otro grupo de servidores de bases de datos.
En este diseño, la mayoría de los recursos, como los repositorios de documentos, se comparten entre el clúster a través de un sistema de archivos compartido. Por supuesto, la configuración del almacenamiento de todos los nodos del clúster debe estar alineada y apuntar a las mismas ubicaciones en el sistema de archivos compartidos.
El índice de texto completo no se puede colocar en el sistema de archivos compartidos, por lo que cada nodo continúa manteniendo un índice local y parcial y, en el momento de la búsqueda, se contactará a todos los demás nodos para recopilar los resultados indexados en otros lugares (es decir, una búsqueda federada).