")
")
")
Miglior Rendimento
Lo scopo di questo tipo di clustering è quello di aumentare le prestazioni quando i miglioramenti su un singolo server non sarebbero sufficienti. Uno scenario tipico è quando si hanno molti utenti simultanei o un repositorio di documenti molto grande da indicizzare.
LogicalDOC supporta il clustering per massimizzare le prestazioni, distribuendo i carichi di CPU e RAM tra un insieme di nodi chiamato cluster. La maggior parte dello stress in una grande installazione è dovuto alle operazioni di analisi, indicizzazione e ricerca. Per questo motivo, ogni nodo LogicalDOC gestirà il proprio indice full-text e una ricerca federata si estenderà su tutti i nodi.
È necessario configurare almeno due istanze distinte di LogicalDOC in esecuzione nella stessa rete su nodi diversi. Devi anche mettere un sistema di bilanciamento del carico hardware davanti al cluster per distribuire uniformemente le richieste.
Implementazione con un file system locale
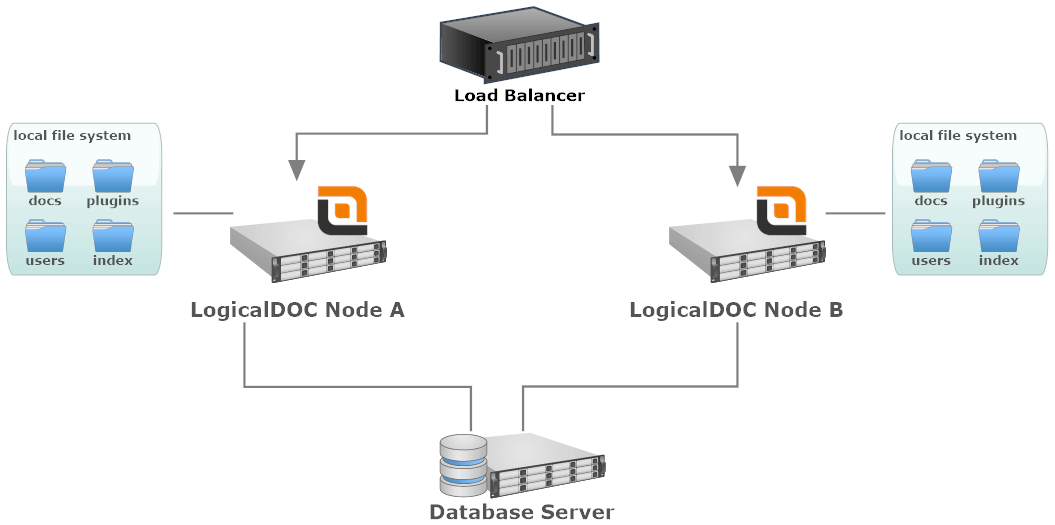
- Load Balancer: un componente software o hardware che distribuisce uniformemente il traffico in entrata ai nodi del cluster.
- LogicalDOC Node: ogni nodo è una singola istanza LogicalDOC installata in un server dedicato. È possibile utilizzare server fisici o virtuali.
- Local File System: il file system collegato a un nodo specifico. Potrebbe essere un'unità locale o qualsiasi altro dispositivo di archiviazione non condiviso con altri nodi del cluster.
- Database Server: il database è condiviso tra tutti i nodi. Potrebbe essere un singolo nodo o un altro cluster di server di database.
In questo layout la maggior parte di tutte le risorse, come i repositori dei documenti, sono completamente locali, quindi i tuoi documenti verranno archiviati fisicamente tra i diversi nodi. Quando un nodo richiede un documento o qualsiasi altra risorsa che non trova localmente, comunicherà con gli altri nodi per ottenerlo. Allo stesso tempo ogni nodo mantiene un indice full-text parziale quindi al momento della ricerca, tutti gli altri nodi verranno contattati per raccogliere i risultati indicizzati altrove (cioè una ricerca federata).
Attenzione
Siccome i documenti vengono archiviati in nodi diversi, si potrebbe generare molto traffico nella tua LAN quando verranno trasferiti da un nodo all'altro. Pertanto, si suggerisce di attivare l'opzione Cache nella configurazione del clustering di ciascun nodo per ottimizzare i trasferimenti.
Implementazione con un file system condiviso
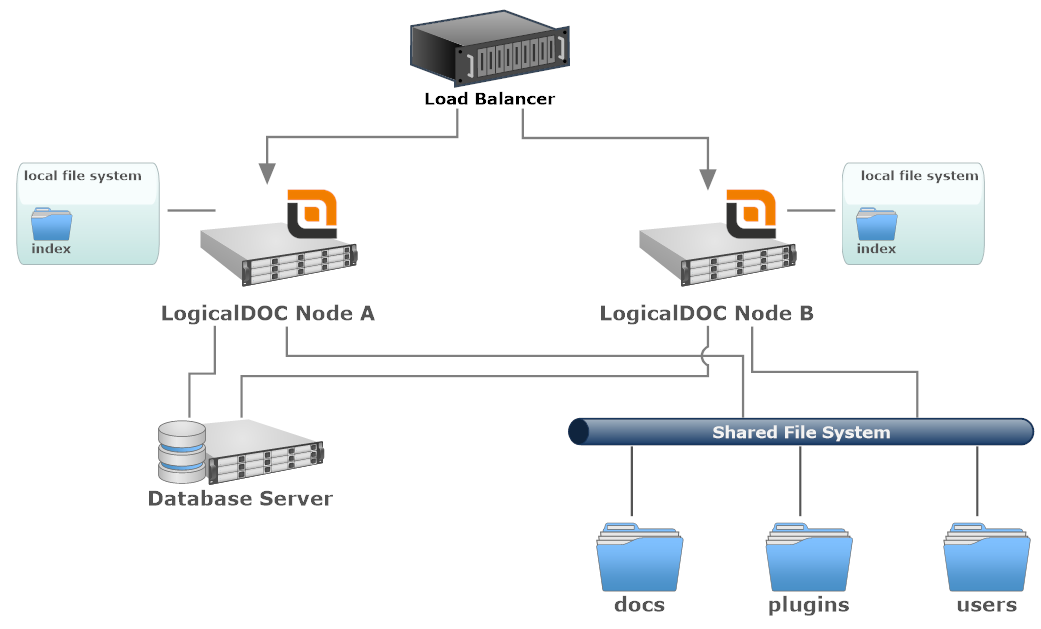
- Load Balancer: un componente software o hardware che distribuisce uniformemente il traffico in entrata ai nodi del cluster.
- LogicalDOC Node: ogni nodo è una singola istanza LogicalDOC installata in un server dedicato. È possibile utilizzare server fisici o virtuali.
- Local File System: il file system collegato a un nodo specifico. Potrebbe essere un'unità locale o qualsiasi altro dispositivo di archiviazione non condiviso tra altri nodi del cluster.
- Shared File System: un file system condiviso comune a tutti i nodi. È possibile utilizzare più volumi e/o NAS dedicati.
- Database Server: il database è condiviso tra tutti i nodi. Potrebbe essere un singolo nodo o un altro cluster di server di database.
In questo layout, la maggior parte delle risorse, come i repositorio dei documenti, sono condivise tra il cluster tramite un file system condiviso. Naturalmente, la configurazione degli storage di tutti i nodi del cluster deve essere allineata e puntare alle stesse posizioni nel file system condiviso.
L'indice full-text non può essere inserito nel file system condiviso, quindi ogni nodo continua a mantenere un indice locale e parziale e al momento della ricerca, tutti gli altri nodi verranno contattati per raccogliere i risultati indicizzati altrove (che un ricerca federata).