")
")
")
Natural Language Processing
Natural Language Processing, or simply NLP, is a class of AI model designed to process naturally written texts.
NLP enables computers to understand, interpret, and generate human language. It bridges the gap between human communication and machine understanding, allowing machines to read text, hear speech, interpret it, and even respond in natural ways. NLP combines computational linguistics with statistical, machine learning, and deep learning models to process and analyze large amounts of natural language data.
By using NLP, systems can perform tasks like language translation, sentiment analysis, speech recognition, chatbot conversations, and document summarization.
How Natural Language Processing Works
NLP involves a series of techniques and steps that convert unstructured human language into structured data that machines can understand and act upon.
Text Processing
- Tokenization: breaking text into words or phrases.
- Stop-word Removal: filtering out common words (like "and", "the") that carry little meaning.
- Stemming/Lemmatization: reducing words to their base or root form.
Syntax and Semantics Analytics
- Syntax Analysis (Parsing) involves analyzing the grammatical structure of a sentence, identifying parts of speech and relationships between words.
- Semantic Analysis focuses on understanding the meaning behind words, sentences, and context.
Feature Extraction
Relevant features are extracted from the text, such as keywords, named entities (e.g., people, places), and sentiment indicators. These features serve as input for machine learning models.
Modeling and Interpretation
Using techniques such as classification, clustering, or neural networks, the system interprets the text and performs a task, like identifying sentiment, generating responses, or categorizing content.
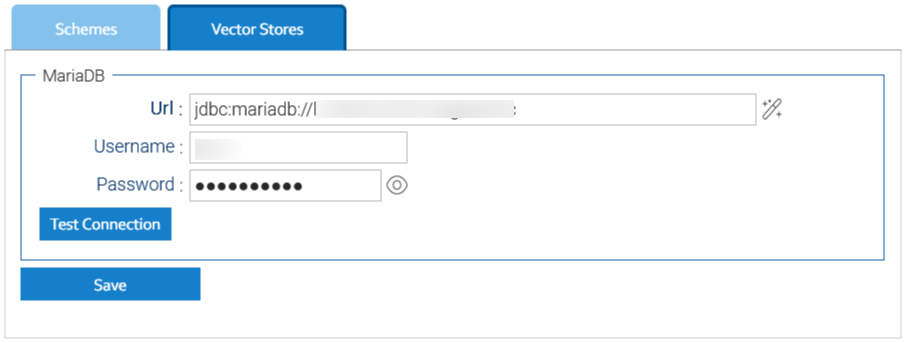
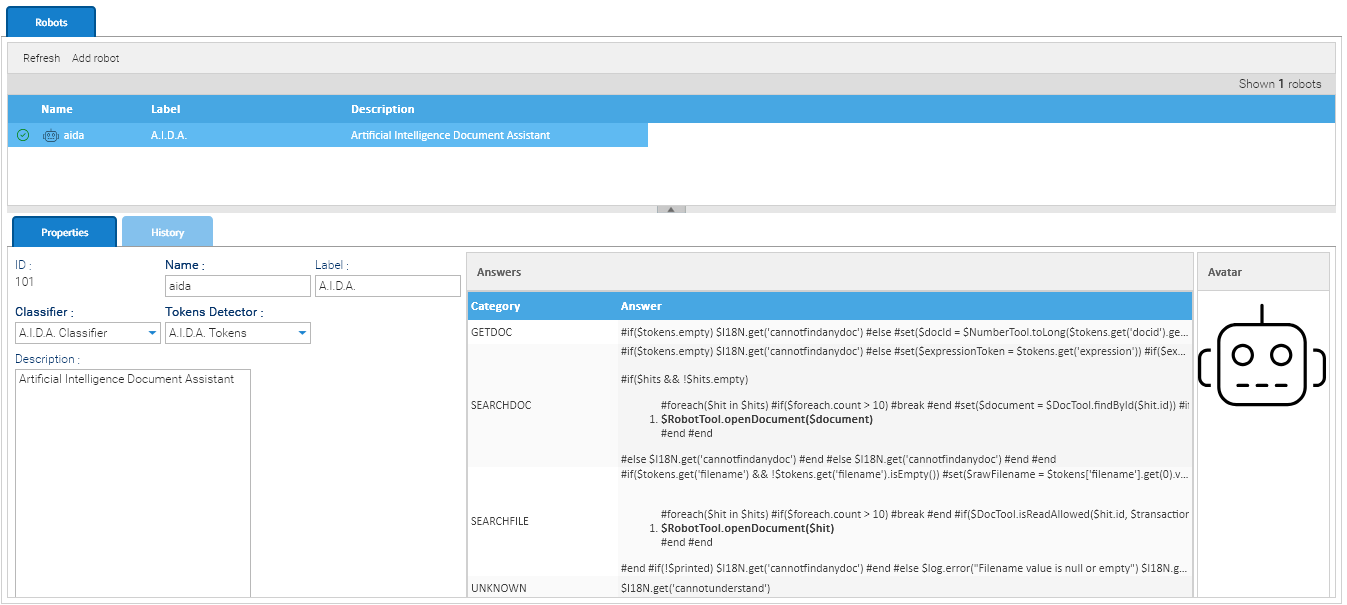
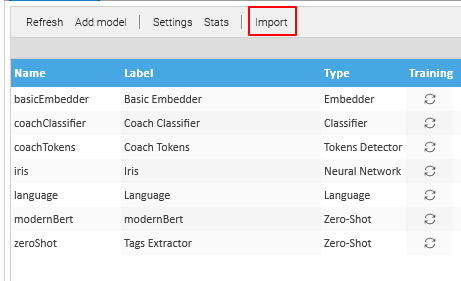
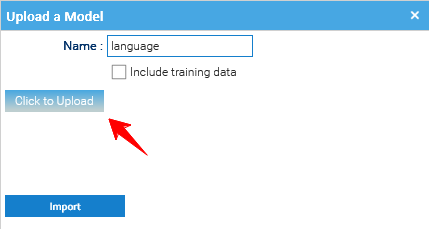
At the time of this writing, there are different types of NLP models, each designed to solve specific language-related tasks. The models used in LogicalDOC are: