")
")
")
Modelli di IA
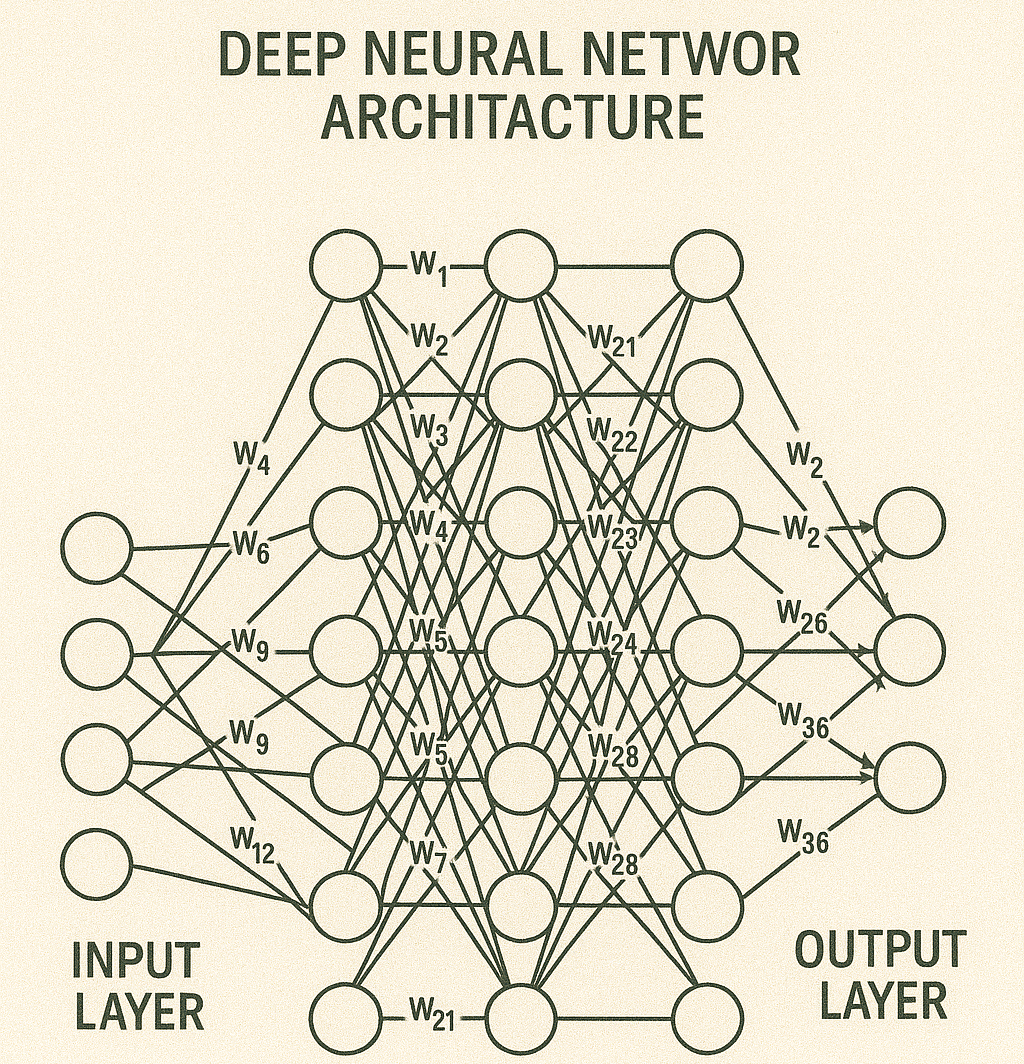
Un modello di intelligenza artificiale (o semplicemente modello) rappresenta un programma addestrato su un insieme di dati per riconoscere determinati schemi o prendere determinate decisioni senza ulteriore intervento umano.
È possibile gestire i modelli in Amministrazione > Intelligenza Artificiale > Modelli.
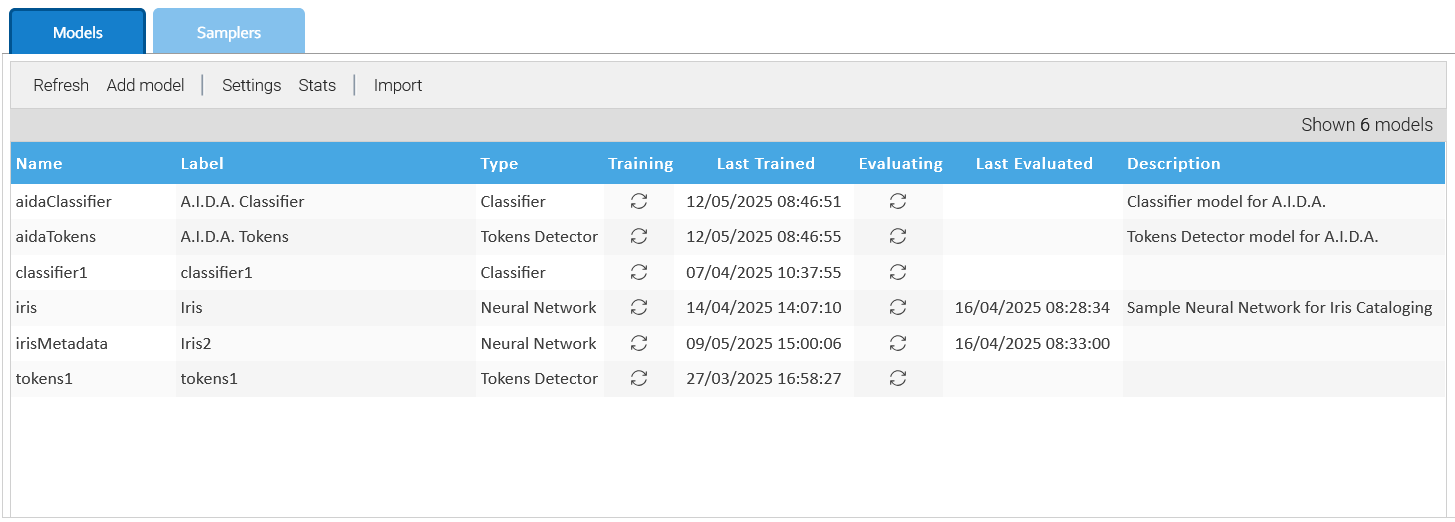
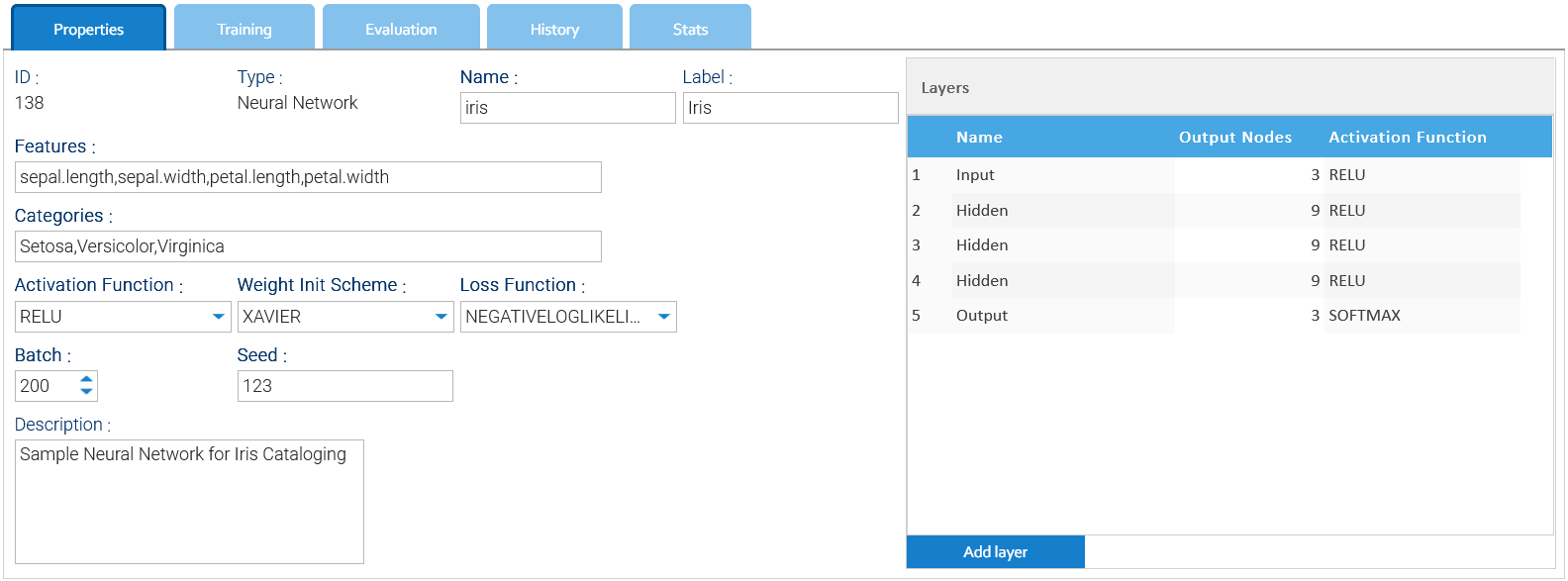
È possibile contare su diversi tipi di modelli per implementare specifici algoritmi di intelligenza artificiale, con impostazioni diverse.
Impostazioni
Puoi creare i tuoi modelli cliccando su Aggiungi modello oppure modificarne uno esistente.
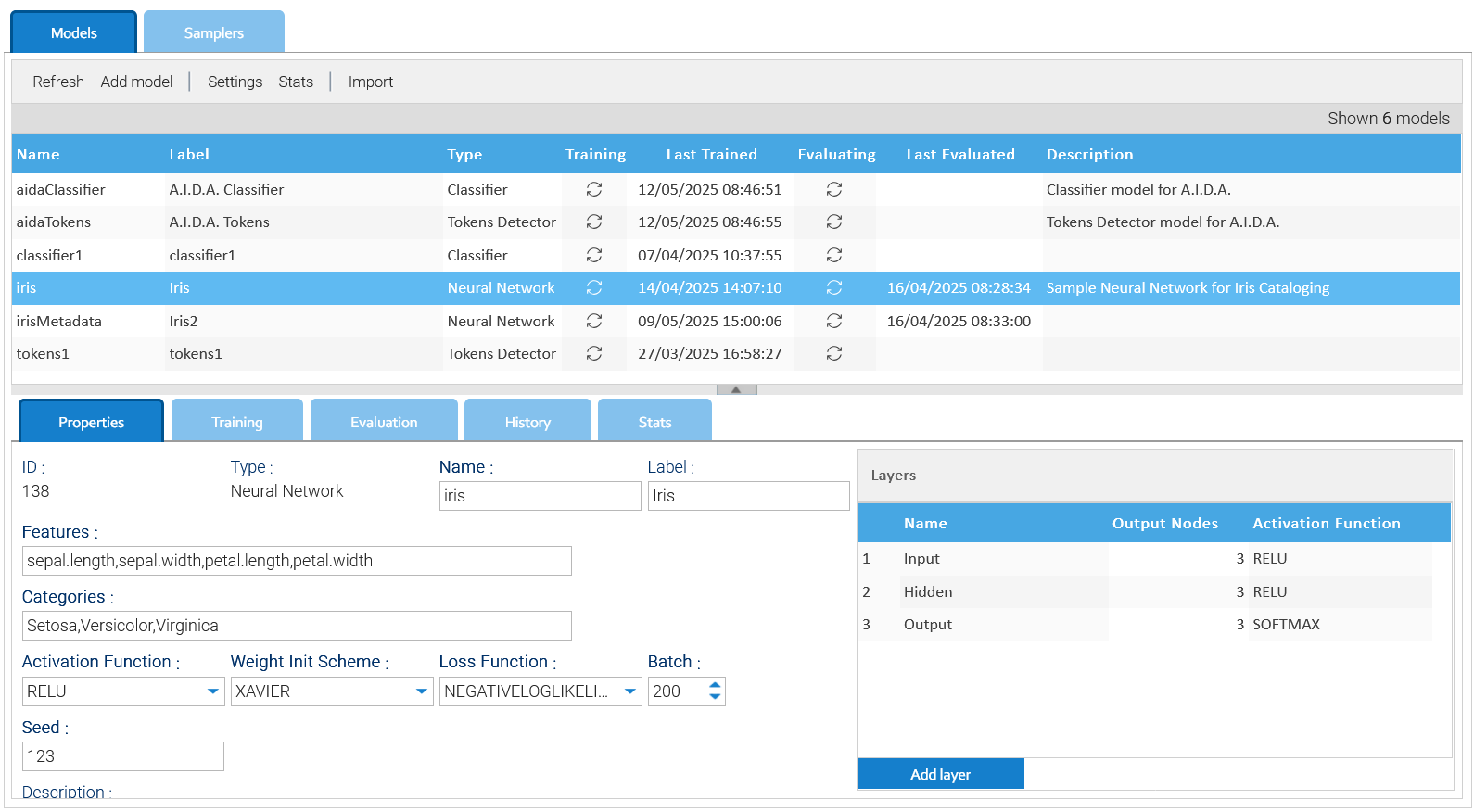
Il pannello delle impostazioni è diverso a seconda del tipo di modello e consente di configurarne correttamente tutti gli aspetti.
Addestramento
Poiché ogni modello deve essere prima addestrato, la scheda Addestramento è il luogo in cui si impartiscono istruzioni al sistema su come eseguire tale attività.
L'impostazione più importante è il Campionatore, che consente di scegliere tra l'elenco dei campionatori creati in precedenza.
Quasi tutti i modelli richiedono più cicli di addestramento; per farlo è necessario specificare in Epoche il numero di iterazioni desiderate durante l'addestramento del modello.
Maggiore è il numero di epoche modali inserite, più accurato sarà il modello ottenuto, ma l'operazione di addestramento richiederà più tempo.
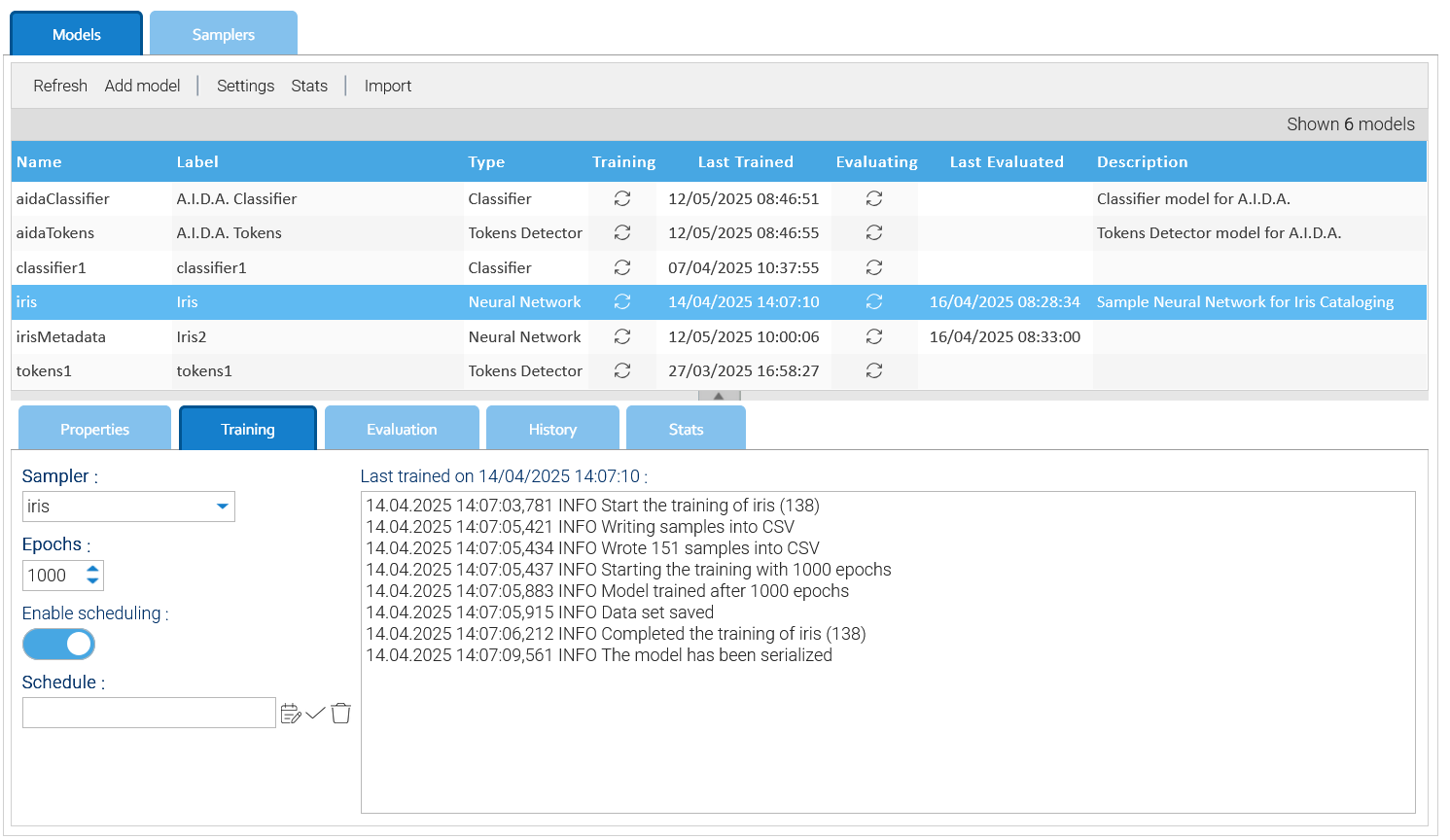
Se il set di dati utilizzato per addestrare i modelli cambia regolarmente, sarebbe opportuno contrassegnare l'opzione Abilita la pianificazione e fornire una pianificazione, in questo modo il modello verrà addestrato costantemente.
In qualsiasi momento è possibile forzare manualmente l'allenamento tramite la voce Avvia addestramento del menu contestuale.
Risultati del Training
Il completamento della formazione si riflette nella griglia dei modelli, ma anche nell'area del registro della scheda di formazione, dove è possibile vedere come sono state eseguite le operazioni.
Il modello addestrato viene quindi salvato in LogicalDOC stesso come un normale documento nella cartella predefinita /Default/ai-models e in altri file a seconda della natura del modello.
È possibile modificare il percorso in cui LogicalDOC salva i risultati della formazione utilizzando il pulsante Impostazioni della barra degli strumenti.
Interrogazione del Modello
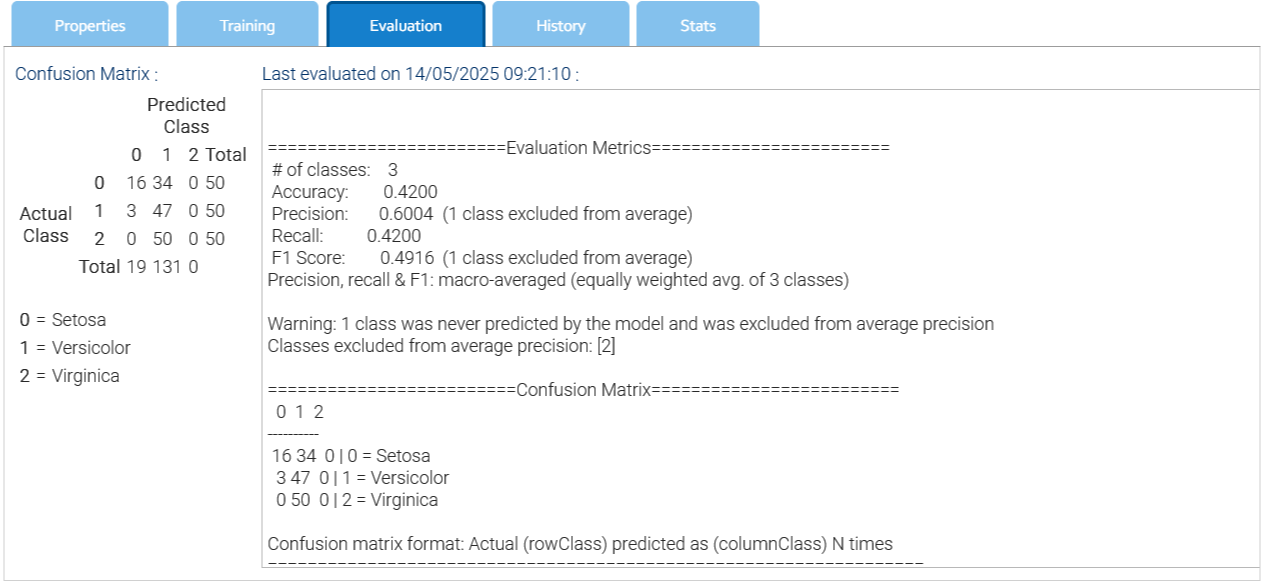
Dopo aver addestrato il modello, è possibile interrogarlo. Per farlo, è sufficiente selezionare la voce Interroga il modello dal menu contestuale per aprire la finestra di dialogo e inserire il campione da valutare.
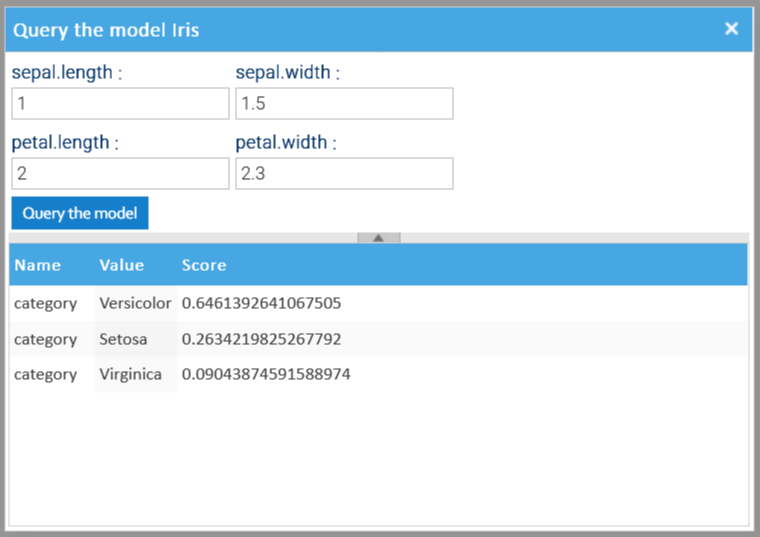
Di seguito vengono visualizzati i possibili risultati, ordinati in base al punteggio decrescente.
Cronologia e Statistiche
Nella scheda Cronologia trovi l'elenco degli eventi relativi al modello corrente.
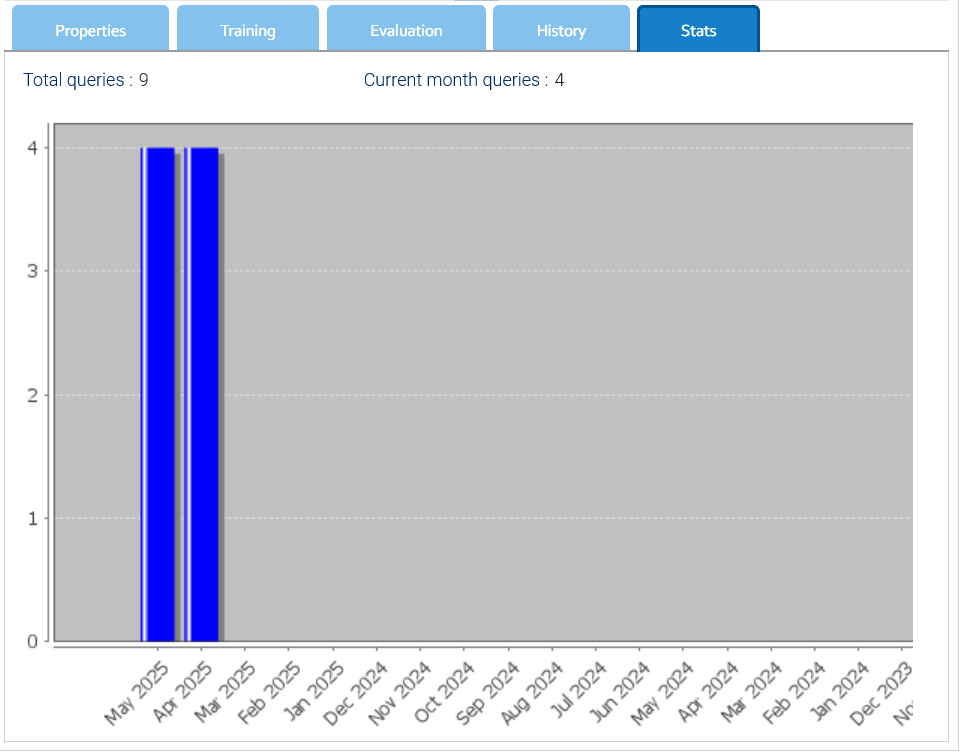
All'interno della scheda Statistiche è presente una rappresentazione grafica del totale delle query al mese.
Esportazione e Importazione
I modelli possono essere esportati e importati, questa funzionalità è stata pensata per consentirti di preparare e addestrare i tuoi modelli in un'installazione LogicalDOC e poi importarli già addestrati nel sistema di produzione.
Per esportare un modello, basta selezionare l'opzione Esporta dal menu contestuale. Verrà scaricato un archivio compresso contenente sia la definizione del modello che il suo training.
In un sistema di destinazione in cui si desidera importare un modello precedentemente esportato, fare clic sul pulsante Importa della barra degli strumenti: verrà chiesto di caricare l'archivio e di fornire il nome per il nuovo modello.
Nel caso in cui si voglia aggiornare un modello esistente, basta selezionarlo e scegliere la voce Importa dal menù contestuale, verrà quindi caricato l'archivio e sovrascritto il modello corrente.