")
")
")
Modelos de IA
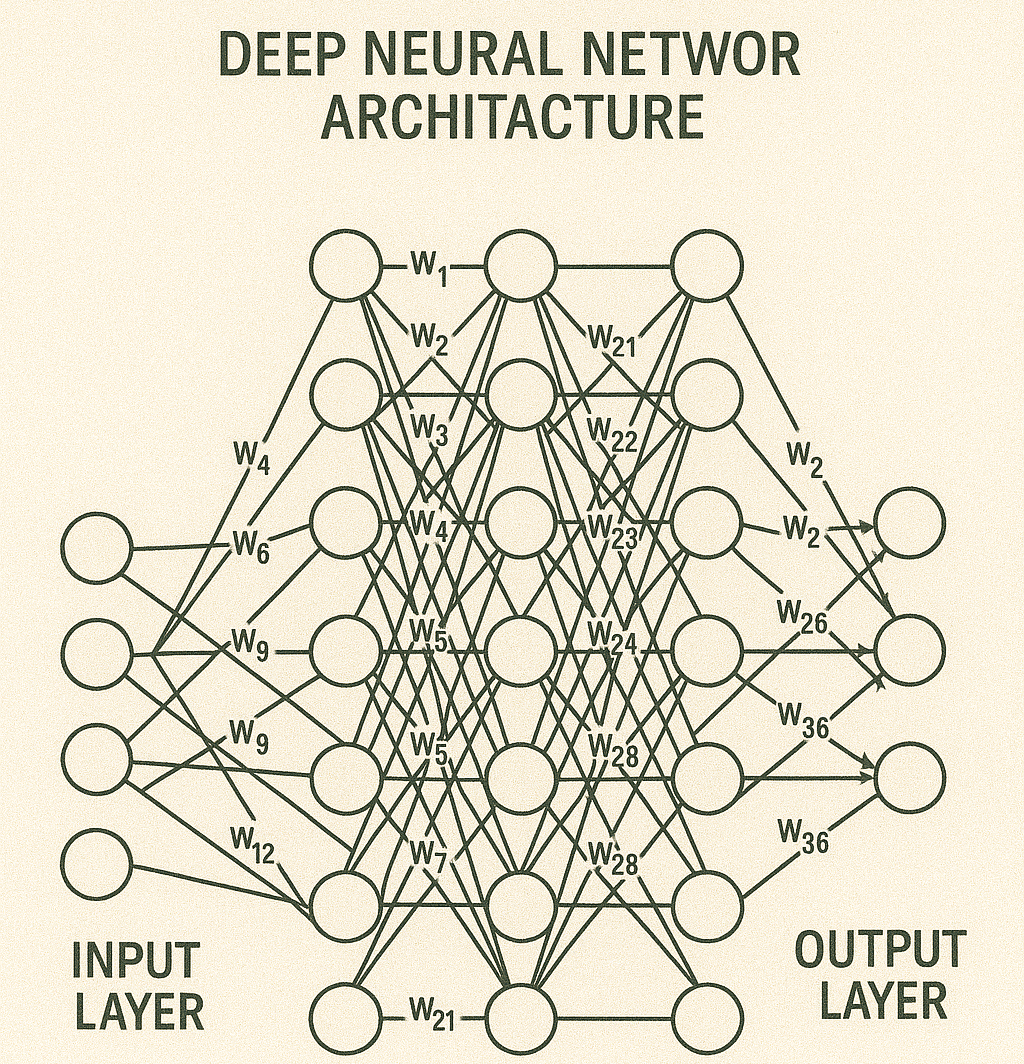
Un modelo de IA (o simplemente modelo) representa un programa que ha sido capacitado en un conjunto de datos para reconocer ciertos patrones o tomar ciertas decisiones sin más intervención humana.
Manejará los modelos en Administración > Inteligencia Artificial > Modelos
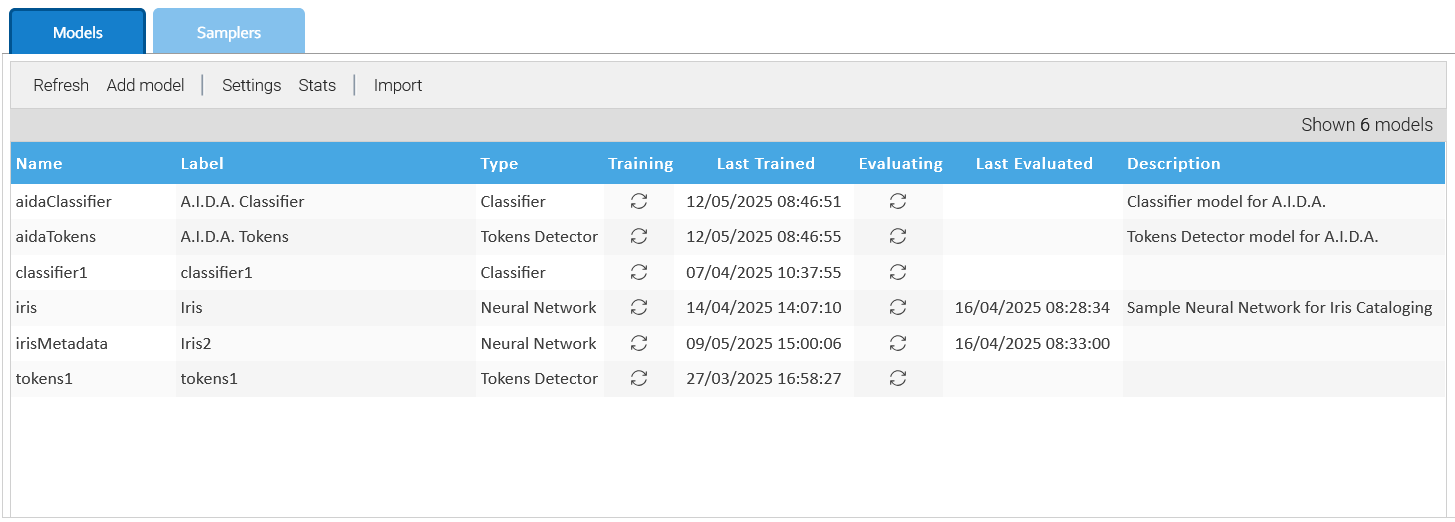
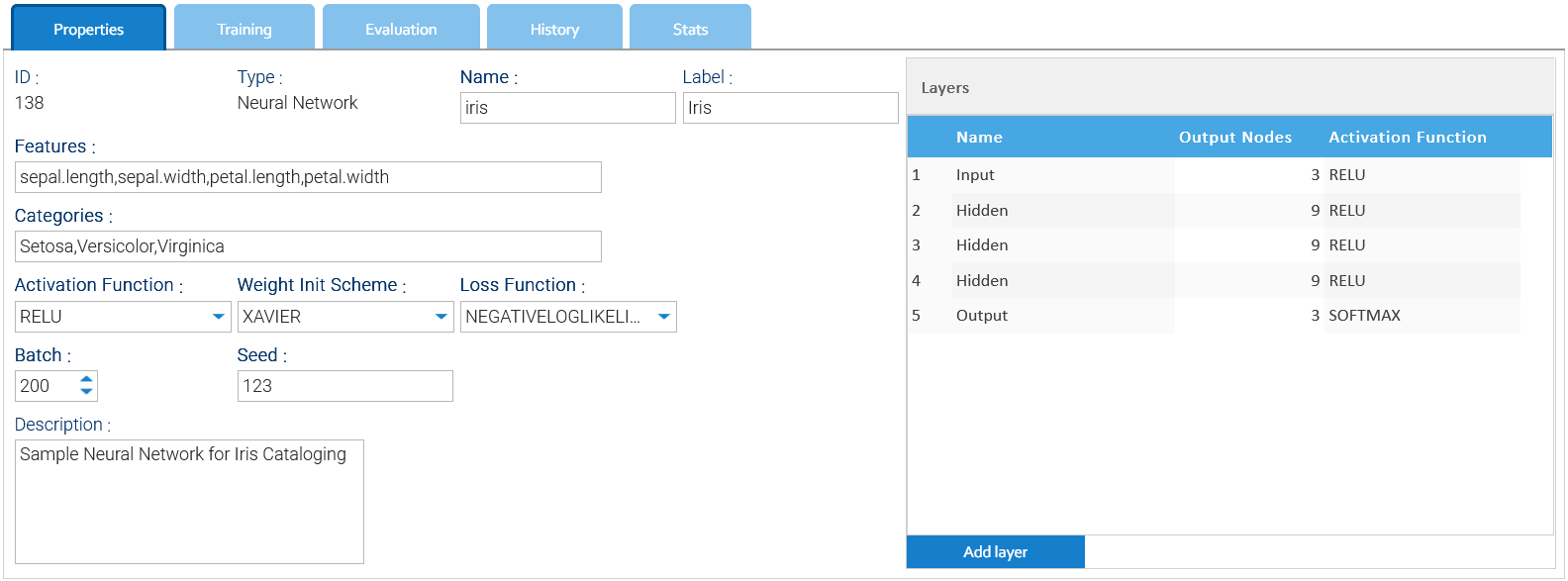
Puede contar con diferentes tipos de modelos para implementar algoritmos de IA específicos, con diferentes configuraciones.
Ajustes
Creas tus propios modelos haciendo clic en Agregar Modelo o editar uno existente.
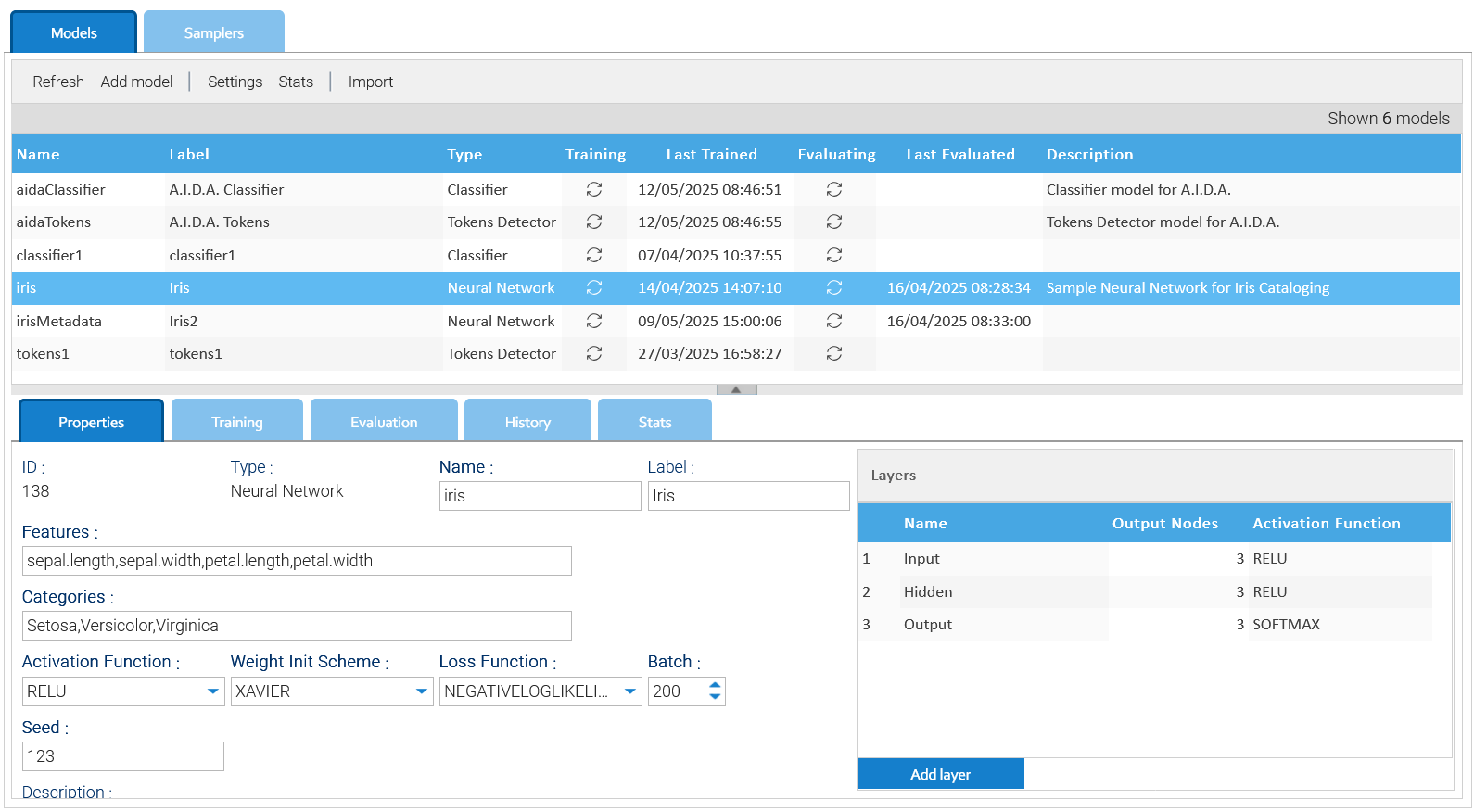
El panel de configuración es diferente dependiendo del tipo de modelo y le permite configurar correctamente todos sus aspectos.
Adiestramiento
Debido a que cada modelo debe ser entrenado primero, la pestaña de Adiestramiento es el lugar donde instruye al sistema sobre como ejecutar dicha actividad.
La configuración más importante es el Sampler que le permite elegir entre la lista de samplers que creó anteriormente.
Todos los modelos requieren más ciclos de entrenamiento, esto especifica en las épocas el número de iteraciones que desea al entrenar el modelo.
Las épocas de modo que pones, más preciso será el modelo, pero la operación de entrenamiento llevará más tiempo.
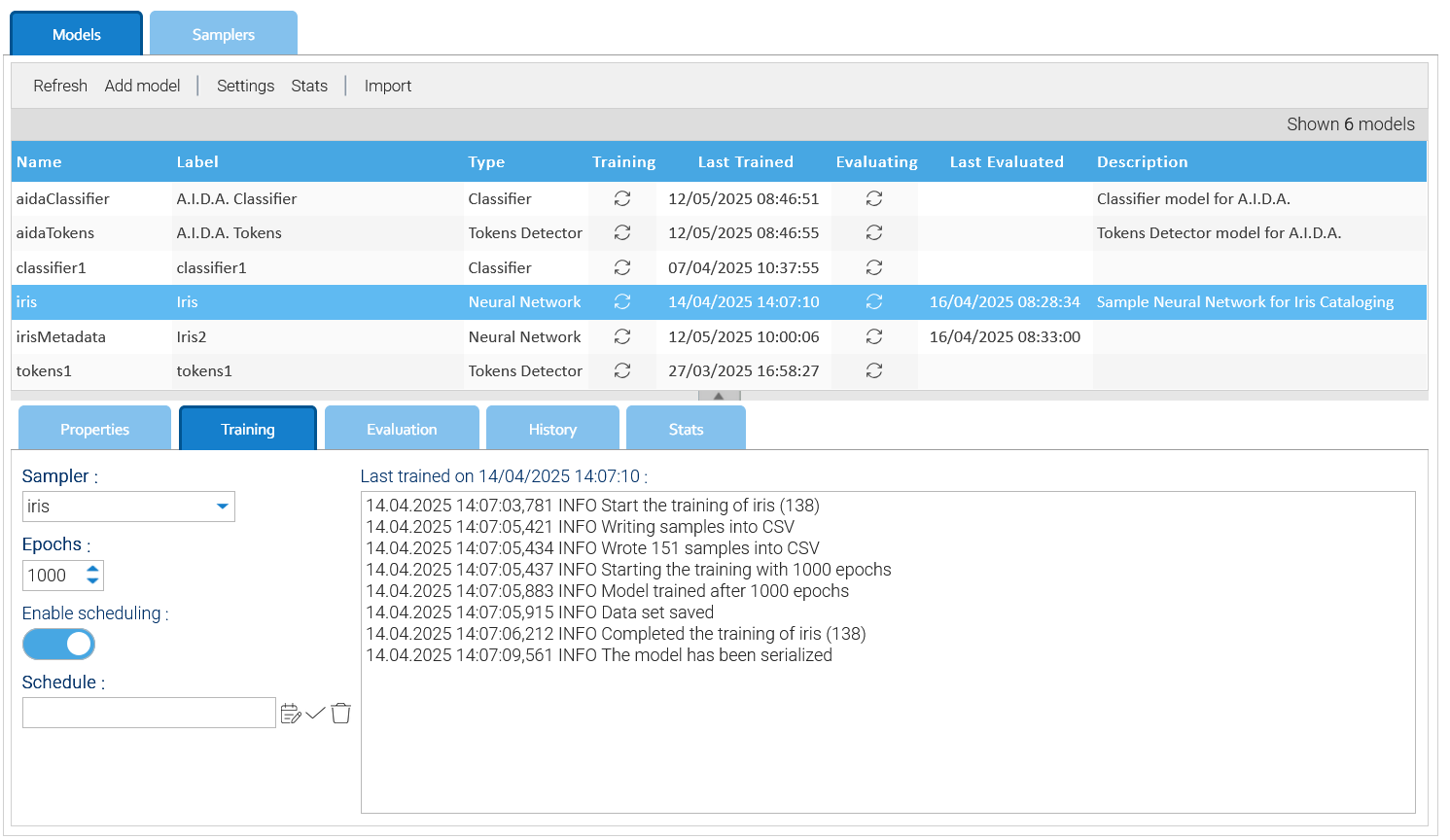
Si el conjunto de datos que utiliza para entrenar los modelos cambia regularmente, sería bueno marcar la opción de Habilitar la programación y proporcionar una programación, de esta manera el modelo estará constantemente capacitado.
En cualquier momento, puede forzar manualmente la capacitación utilizando el elemento de Iniciar adiestramiento del menú contextual.
Resultado del entrenamiento
La finalización de la capacitación se refleja en la cuadrícula de modelos, pero también en el área de registro de la pestaña de capacitación donde puede ver cómo se realizaron las operaciones.
El modelo capacitado se guarda en LogicalDOC en sí mismo como un documento regular en la carpeta /Default/ai-models, así como otros archivos, dependiendo de la naturaleza del modelo.
Puede cambiar la ruta donde LogicalDOC guarda los resultados de la capacitación utilizando el botón Configuración de la barra de herramientas
Consulta del modelo
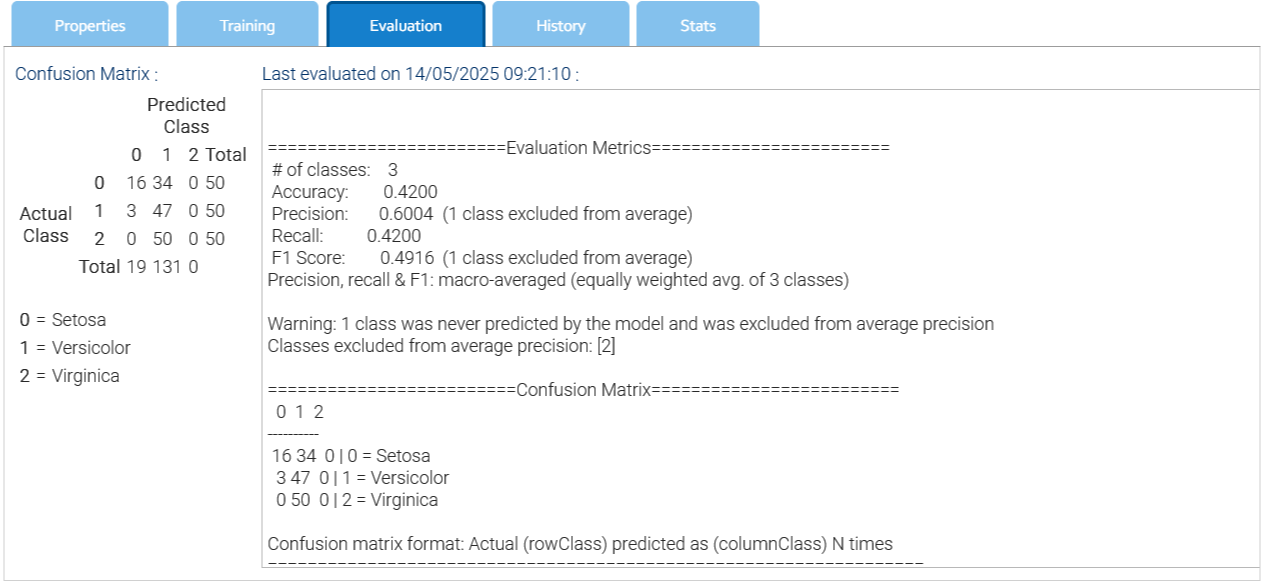
Después de que el modelo haya sido entrenado, puede consultarlo. Para hacerlo, simplemente elija el elemento del menú contextual consulta el modelo para abrir el cuadro de diálogo de consulta e ingrese la muestra para evaluar.
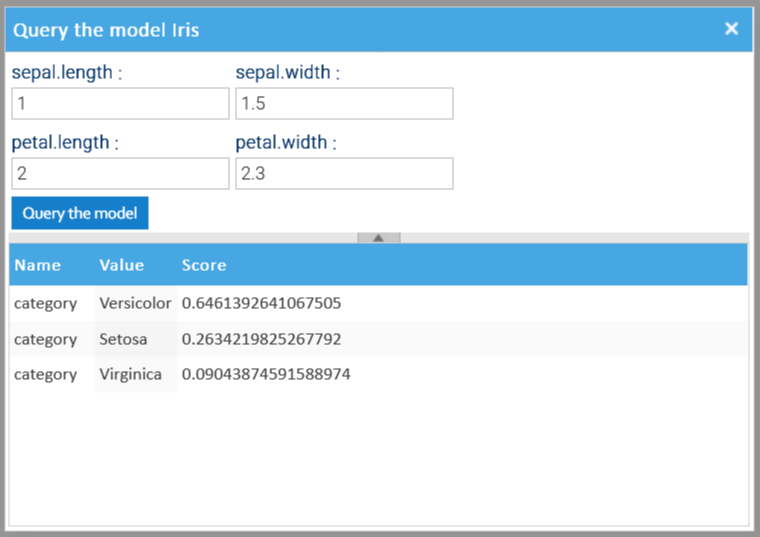
Los posibles resultados se muestran a continuación, ordenados por puntaje descendente.
Historia y Estadísticas
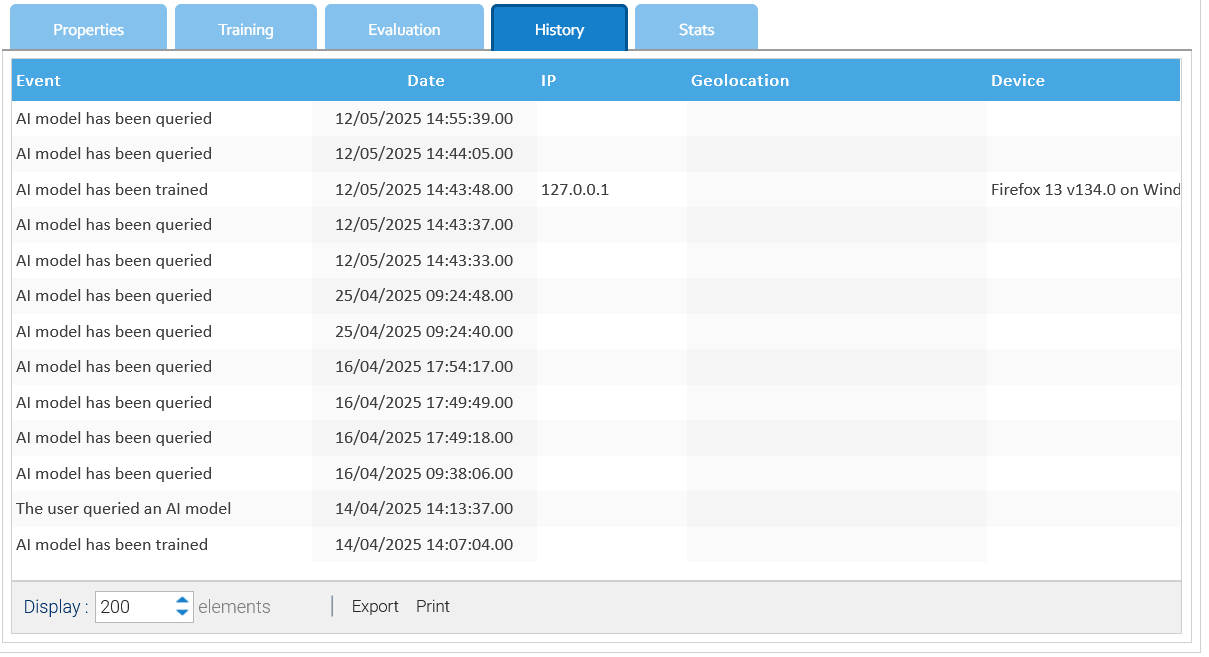
En la pestaña Historial, encuentra la lista de eventos relacionados con el modelo actual.
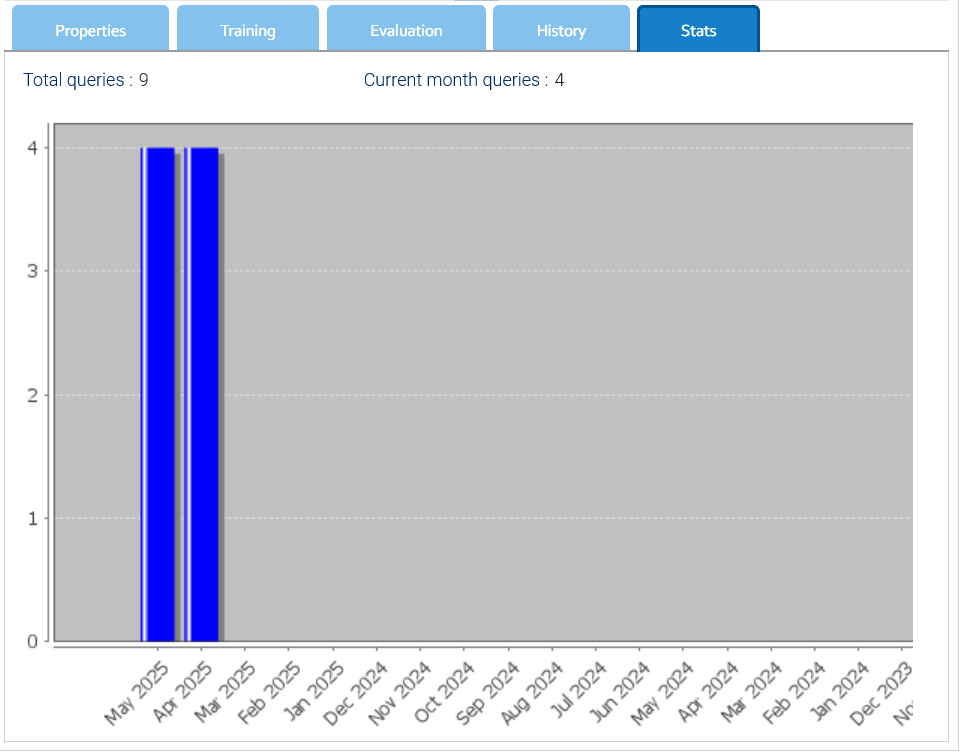
Dentro de la pestaña Estadísticas hay una representación gráfica de las consultas totales por mes.
Exportación e Importación
Los modelos se pueden exportar e importar, se ha pensado que esto le permite preparar y capacitar a sus modelos en una instalación lógica y luego importarlos ya capacitados en el sistema de producción.
Para exportar un modelo, simplemente elija la opción Exportar del menú contextual. Descargará un archivo comprimido que contenga tanto la definición del modelo como su entrenamiento.
En un sistema de destino donde desea importar un modelo exportado previamente, haga clic en el botón Importar la barra de herramientas, se le pedirá que cargue el archivo y proporcione el nombre para el nuevo modelo.
En caso de que desee actualizar un modelo existente, simplemente seleccione y elija el elemento de importación del menú contextual, luego cargará el archivo y sobrescribe el modelo actual.