")
")
")

La arquitectura de alta disponibilidad (HA) es la opción correcta cuando la gestión de documentos se vuelve crítica para el negocio y requiere un tiempo de inactividad mínimo y disponibilidad continua.
La misma arquitectura también se utiliza para implementar un Disaster Recovery (DR) donde el propósito es garantizar la supervivencia del servicio incluso ante un evento grave en el nodo principal.
En ambos casos, la solución es usar dos nodos: el principal, que normalmente se usa para atender el tráfico, y el secundario, en el que se delegan las solicitudes solo si el nodo principal está fuera de servicio.
Para HA, ambos nodos están en la misma LAN, mientras que para DR están ubicados en distintas áreas geográficas.
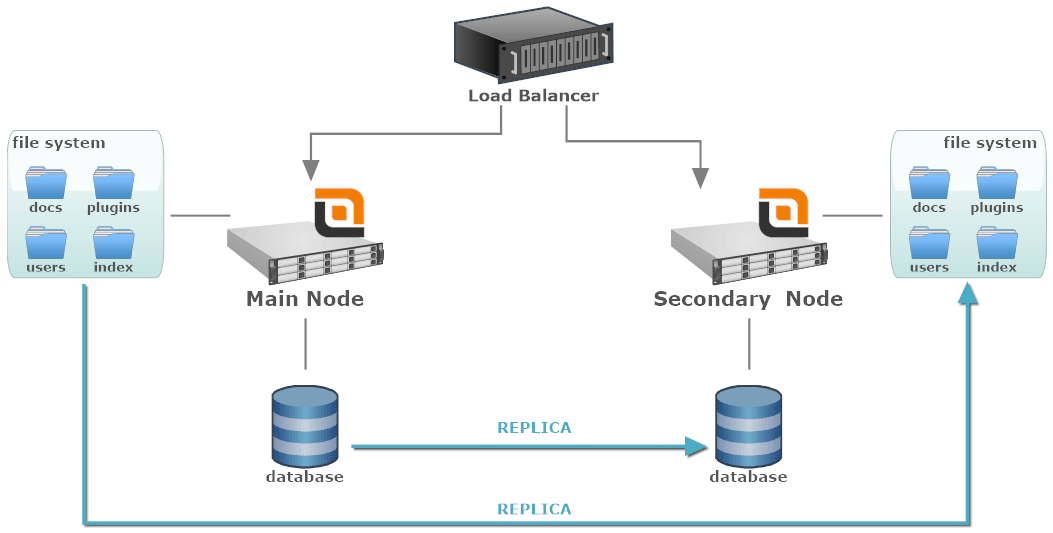
- Load Balancer: un componente de software o hardware que identifica cuando el nodo principal está inactivo y enruta el tráfico entrante al nodo secundario.
- Main Node: la instancia activa que normalmente recibe el tráfico. Puede ser un solo nodo o a su vez un clúster de Mejor Rendimiento.
- Secondary Node: la instancia en espera que recibirá el tráfico cuando el nodo principal no esté disponible.
- Local File System: el sistema de archivos adjunto a un nodo específico. Podría ser una unidad local o cualquier otro dispositivo de almacenamiento que no se comparta entre otros nodos del clúster.
- Database Server: la base de datos se comparte entre todos los nodos. Podría ser un solo nodo u otro grupo de servidores de bases de datos.
Cada nodo tiene su propio almacenamiento y base de datos, pero ambos se replican continuamente desde el nodo principal al secundario. De esta forma, en cuanto el nodo principal deje de estar disponible, el sistema seguirá funcionando gracias al secundario que arranca con los datos de la última replicación.
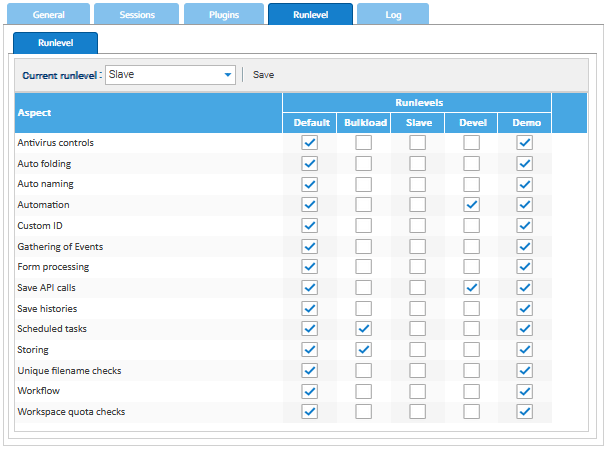
Configurar el nivel de ejecución
Debido a que en este enfoque no hay comunicación entre ambas aplicaciones, no es necesario activar la función de clustering.
El nodo principal debe configurarse para funcionar en el nivel de ejecución Default como normalmente, mientras que el secundario debe funcionar en el nivel de ejecución Slave. Por defecto, la mayoría de los aspectos están deshabilitados en el esclavo, una buena solución para un sistema de solo consulta. Si desea un sistema completamente funcional, puede cambiar al nivel de ejecución a Default tan pronto como el nodo secundario tome el control.
Políticas de replicación
Las dos métricas que normalmente se utilizan para evaluar HA (y también la recuperación ante desastres (DR)) son el objetivo de tiempo de recuperación (RTO) y el objetivo de punto de recuperación (RPO).
- RTO es la duración máxima tolerable de cualquier interrupción.
- RPO es la cantidad máxima de pérdida de datos que se puede tolerar cuando se produce un error.
Existe una diferencia entre los RTO y los RPO que se pueden obtener para admitir una alta disponibilidad frente a la recuperación ante desastres. Con HA, la replicación de datos puede ser síncrona porque los componentes redundantes están ubicados en el entorno LAN. Las bases de datos activas y en espera se pueden actualizar al mismo tiempo, lo que permite recuperaciones completas, automáticas y en tiempo real para satisfacer los RTO y RPO más exigentes. Como resultado, la instancia en espera está "activa" y sincronizada con la instancia activa, por lo que está lista para tomar el control inmediatamente en caso de falla.
Sin embargo, para recuperar sistemas, software y datos en caso de desastre, los componentes redundantes deben estar en una red de área amplia (WAN). Esto es importante porque debe mantener los componentes redundantes en una ubicación geográfica alejada de la instancia activa. Pero con una WAN, la replicación de datos es asíncrona para evitar un impacto negativo en el rendimiento. Esto significa que las actualizaciones de las instancias en espera retrasarán las actualizaciones realizadas en la instancia activa, lo que provocará un retraso durante el proceso de restauración. Dado que los desastres son raros, se puede tolerar cierta demora y depende de (a) qué tan importante es para su negocio lograr el RTO y el RPO más bajos posibles y (b) cuánto presupuesto puede asignar para lograr el mejor RTO y RPO.
Dependiendo del RTO y RPO al que quieras llegar, deberás regular la frecuencia de replicación de los datos del nodo principal al secundario.