L'architettura High Availability (HA) è l'opzione giusta quando la gestione dei documenti diventa business-critical e richiede tempi di inattività minimi e disponibilità continua.
La stessa architettura viene utilizzata anche per implementare un Disaster Recovery (DR) dove lo scopo è quello di garantire la sopravvivenza del servizio anche a fronte di un grave evento sul nodo principale.
In entrambi i casi la soluzione è quella di utilizzare due nodi: quello principale che viene normalmente utilizzato per servire il traffico e quello secondario a cui le richieste vengono delegate solo se il nodo principale è fuori servizio.
Per l'HA entrambi i nodi sono nella stessa LAN mentre per il DR si trovano in aree geografiche distinte.
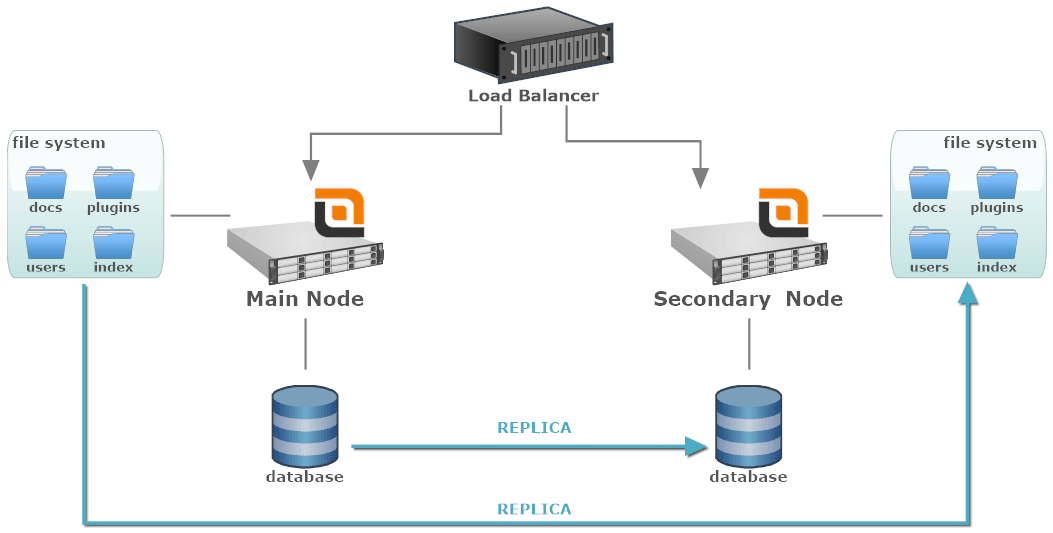
- Load Balancer: un componente software o hardware che identifica quando il nodo principale è inattivo e instrada il traffico in entrata al nodo secondario.
- Main Node: l'istanza attiva che normalmente riceve il traffico. Può essere un singolo nodo o, a sua volta, un cluster Miglior Rendimento.
- Secondary Node: l'istanza di standby che riceverà il traffico quando il nodo principale non è disponibile.
- Local File System: il file system collegato a uno specifico nodo. Potrebbe essere un'unità locale o qualsiasi altro dispositivo di archiviazione non condiviso tra altri nodi del cluster.
- Database Server: il database è condiviso tra tutti i nodi. Potrebbe essere un singolo nodo o un altro cluster di server di database.
Ogni nodo ha il proprio archivio e database, ma entrambi vengono continuamente replicati dal nodo principale a quello secondario. In questo modo non appena il nodo principale diventa indisponibile, il sistema continuerà a funzionare grazie a quello secondario che parte con i dati dell'ultima replica.
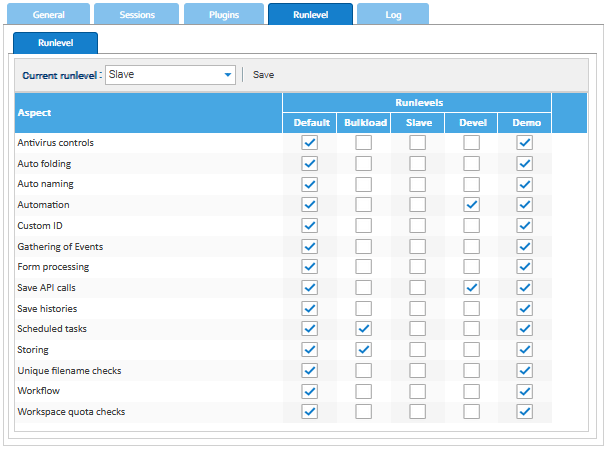
Imposta il livello di esecuzione
Poiché in questo approccio non c'è comunicazione tra entrambe le applicazioni, non è necessario attivare la funzionalità di clustering.
Il nodo principale dovrebbe essere configurato per funzionare nel livello di esecuzione Default come di consueto, mentre il secondario dovrebbe funzionare nel livello di esecuzione Slave. Di default, la maggior parte degli aspetti è disabilitata nello Slave, una buona soluzione per un sistema di sola consultazione. Se si desidera un sistema completamente funzionante, è possibile passare al livello di esecuzione Default non appena il nodo secondario assume il controllo.
Politiche di replicazione
Le due metriche normalmente utilizzate per valutare l'HA (e anche il Disaster Recovery (DR)) sono il Recovery Time Objective (RTO) e il Recovery Point Objective (RPO).
- RTO è la durata massima tollerabile di qualsiasi interruzione.
- RPO è la quantità massima di perdita di dati che può essere tollerata quando si verifica un errore.
Esiste una differenza tra RTO e RPO che è possibile ottenere per supportare la disponibilità elevata rispetto al ripristino di emergenza. Con HA, la replica dei dati può essere sincrona perché i componenti ridondanti si trovano nell'ambiente LAN. I database attivi e in standby possono essere aggiornati contemporaneamente, consentendo recuperi completi, automatici e in tempo reale per soddisfare gli RTO e gli RPO più esigenti. Di conseguenza, l'istanza di standby è "calda" e sincronizzata con l'istanza attiva, quindi è pronta a subentrare immediatamente in caso di errore.
Tuttavia, per ripristinare sistemi, software e dati in caso di emergenza, i componenti ridondanti devono trovarsi su una WAN (Wide Area Network). Questo è importante perché è necessario mantenere i componenti ridondanti in una posizione geografica lontana dall'istanza attiva. Ma con una WAN, la replica dei dati è asincrona per evitare un impatto negativo sulle prestazioni di throughput. Ciò significa che gli aggiornamenti alle istanze in standby ritarderanno gli aggiornamenti effettuati sull'istanza attiva, causando un ritardo durante il processo di ripristino. Poiché i disastri sono rari, un certo ritardo può essere tollerabile e dipende da (a) quanto sia fondamentale per la tua azienda raggiungere l'RTO e l'RPO più bassi possibili e (b) quanto budget puoi allocare per ottenere i migliori RTO e RPO.
A seconda dell'RTO e dell'RPO che vuoi raggiungere, dovresti regolare la frequenza della replica dei dati dal nodo principale a quello secondario.