")
")
")
Embeddings
Gli embedding sono vettori che rappresentano interi documenti o frammenti di essi in uno spazio vettoriale continuo. Questa rappresentazione numerica è necessaria per dedurre in modo efficiente le similitudini tra i documenti e implementare funzionalità come la Ricerca Semantica.
Ciò significa che LogicalDOC deve calcolare tutti questi embedding per i documenti nel repositorio e salvarli nel Vector Store, la cui configurazione è un requisito.
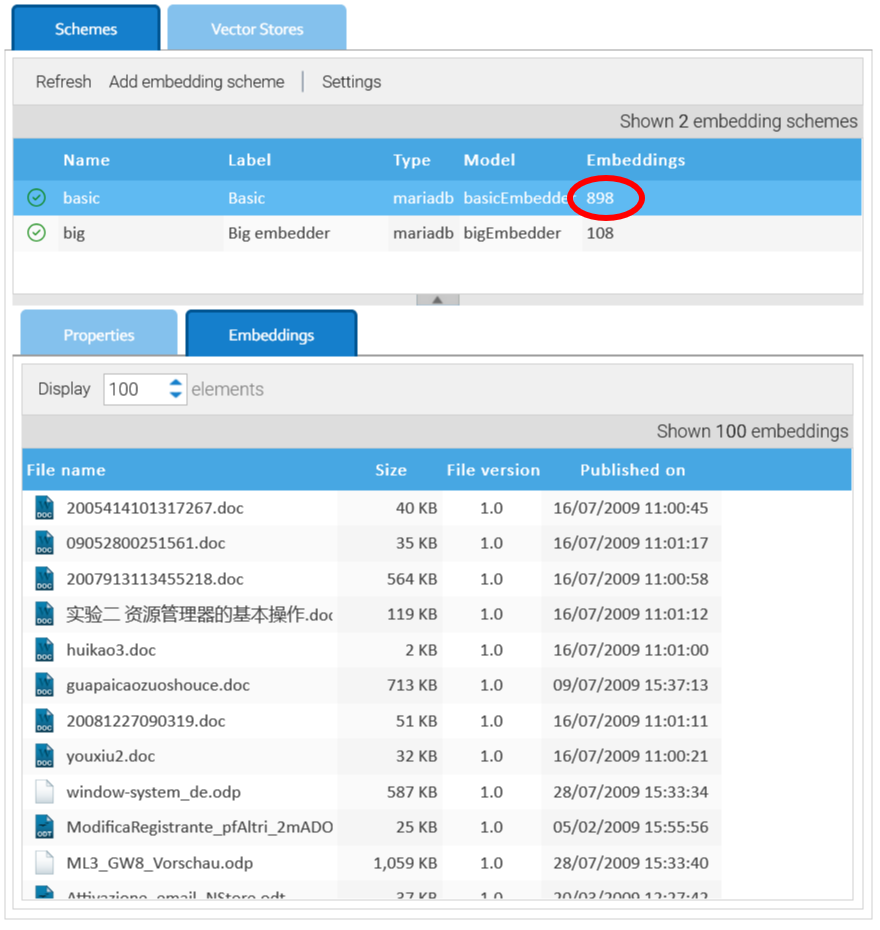
Schemi di Embedding
Il processo di calcolo di un embedding di un documento non è univoco, ma dipende dal modello di embedding utilizzato.
In Amministrazione > Intelligenza Artificiale > Embedding, è possibile gestire diversi schemi di embedding, ognuno dei quali indica a LogicalDOC come elaborare i documenti con uno specifico modello di embedding.
Quando si crea un nuovo schema facendo clic su Aggiungi schema di embedding, verrà richiesto di specificare uno dei modelli di embedding disponibili.
Al momento della stesura di questo documento, è possibile scegliere tra i modelli Embedder codificati in LogicalDOC stesso o uno dei modelli di embedding disponibili in ChatGPT.
Altre impostazioni comuni sono:
Batch: Numero di documenti elaborati contemporaneamente
Lotto di frammenti: Quanti blocchi vengono aggiunti contemporaneamente all'archivio vettoriale
Elaborazione in background
Come l'indicizzazione full-text, anche il calcolo degli embeddings richiede un uso intensivo della CPU e viene quindi eseguito dall'attività pianificata Embedder.
Fare clic sul pulsante Impostazioni per visualizzare alcuni parametri di configurazione che regolano il funzionamento dell'attività.
Man mano che i vettori vengono calcolati e salvati nell'archivio vettoriale, è possibile visualizzarli nel contatore e nel pannello Incorporamenti.