")
")
")
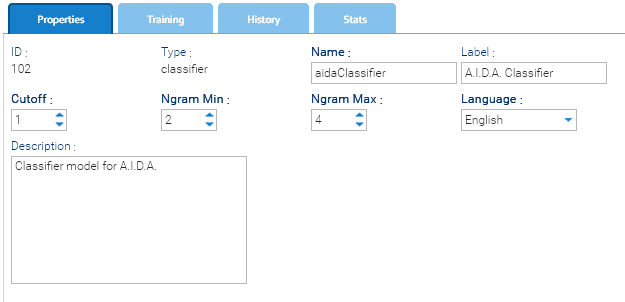
Detector de Tokens
El detector de tokens es un modelo de lenguaje natural especializado, diseñado para identificar y extraer fragmentos específicos de información, llamados tokens, de una oración. Se utiliza para detectar datos estructurados como identificadores, nombres, fechas o códigos incrustados en texto de lenguaje natural.
A diferencia de un clasificador, que categoriza oraciones completas, el detector de tokens se centra en marcar y etiquetar subsecciones de una oración. Esto es especialmente útil para aplicaciones que necesitan extraer valores de las solicitudes del usuario, como identificadores de documentos o referencias.
Cómo funciona el detector de tokens
El Detector de Tokens se entrena con oraciones etiquetadas donde los tokens de interés están claramente marcados con un formato especial. Cada token detectado se encierra en las etiquetas <START:label> y <END>. Estas indican tanto los límites del token como el tipo de información que se extrae. En concreto, estas etiquetas (<START:label> y <END>) enseñan al sistema a reconocer estructuras y valores similares en texto nuevo e inédito.
Ejemplos:
I am searching for the document with id <START:docId> 12356897 </START:docId>, please send it to me.
All employees are encouraged to find doc with id <START:docid> 0023 <END> on the HR portal.
Interested faculty and graduate students can find document with id <START:docid> 1250 <END>. Please open file titled <START:filename> launch_brief.txt <END>.
The revised pipeline is presented in the document <START:filename> ingestion_workflow_diagram_v2.pdf <END>.
To explore the many benefits of developing a consistent reading habit, see the document called <START:filename> reading-benefits.txt <END>. Please, retrieve any documents about <START:expression> 1250 <END> paper .
Locate the finance policy document containing <START:expression> "card*" <END> usage rules and restrictions.
I need you to find all compliance documentation that specifies <START:expression> dev* <END> for our legal counsel.
Como se muestra arriba, el detector utiliza ejemplos etiquetados donde los tokens están etiquetados explícitamente. Por lo tanto, aprende a reconocer estos tipos de tokens basándose en:
- Posición de la palabra
- Forma de la palabra (números, mayúsculas, etc.)
- Contexto del token
Detección de Tokens
Cuando se envía una oración al modelo, este primero la divide en tokens (normalmente palabras o signos de puntuación) mediante un tokenizador específico del lenguaje. Este paso es esencial para el reconocimiento preciso de los límites de los tokens. El modelo entrenado escanea la oración tokenizada e identifica los grupos de palabras que coinciden con los patrones aprendidos. Cada grupo se devuelve junto con:
- La etiqueta del token (p. ej., docid)
- El valor (p. ej., 12356897)
- Una puntuación de confianza