")
")
")
Embedder
Los modelos de la clase Embedder permiten la asignación de documentos completos a vectores de longitud fija, lo que posibilita su representación en un espacio vectorial continuo. Esto facilita la comparación y manipulación eficiente de datos textuales en el procesamiento del lenguaje natural (PLN), como las búsquedas semánticas.
Cómo funciona el Embedder
La transformación del contenido de un documento en un vector se realiza mediante el algoritmo Doc2Vec. Este manual no es el lugar adecuado para tratar los detalles de esta técnica, pero puede encontrar mucha literatura sobre el tema.
En pocas palabras, Doc2Vec utiliza una red neuronal específica para crear una representación numérica de un documento (el vector) que, por lo general, se almacenará en un Vector Store. Los documentos similares se representarán mediante dos vectores diferentes pero adyacentes en el espacio vectorial multidimensional.
El Embedder se entrena utilizando párrafos de texto escritos en lenguaje natural, cada párrafo termina con un punto seguido de una línea en blanco:
Ejemplo:
She quickly dropped it all into a bin, closed it with its wooden
lid, and carried everything out. She had hardly turned her back
before Gregor came out again from under the couch and stretched
himself.
This was how Gregor received his food each day now, once in the
morning while his parents and the maid were still asleep, and the
second time after everyone had eaten their meal at midday as his
parents would sleep for a little while then as well, and Gregor's
sister would send the maid away on some errand. Gregor's father and
mother certainly did not want him to starve either, but perhaps it
would have been more than they could stand to have any more
experience of his feeding than being told about it, and perhaps his
sister wanted to spare them what distress she could as they were
indeed suffering enough.
Resumen de la configuración del incrustador
Esta sección describe los campos de configuración clave del modelo embedder. Estos ajustes definen cómo se comporta el embedder durante el entrenamiento y cómo interpreta la entrada del usuario.
Propiedades
La pestaña Propiedades de la interfaz del embedder contiene los ajustes de configuración principales que definen el comportamiento del embedder durante el entrenamiento y la incrustación. Estos parámetros influyen en el procesamiento del texto de entrada.
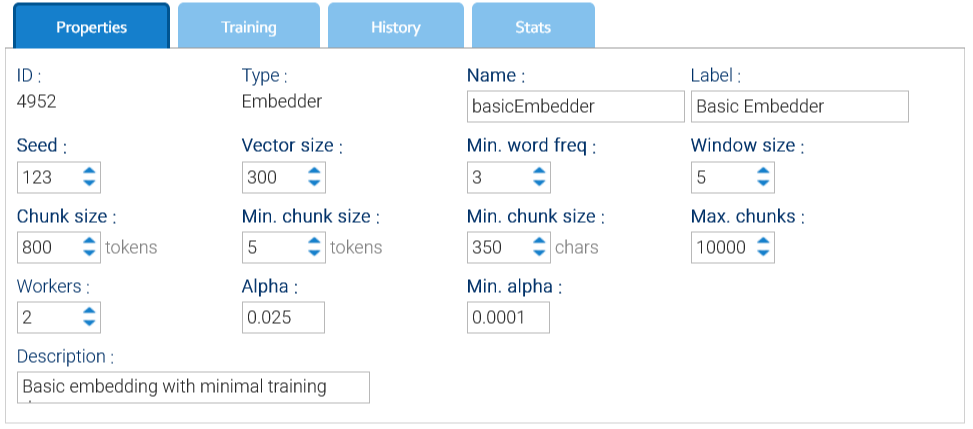
- Semilla: valor utilizado para la generación de números aleatorios
- Trabajadores: número de subprocesos utilizados para el entrenamiento
- Tamaño de la ventana: tamaño de la ventana utilizada por el algoritmo Doc2Vec
- Tamaño del vector: número de elementos en cada vector; debe ser mayor que 300
- Frecuencia mínima de palabras: las palabras que aparezcan con un número menor a este número se descartarán
- Máximo de fragmentos: cada documento se subdivide en fragmentos de tokens; aquí se especifica el número máximo de fragmentos admitidos
- Tamaño del fragmento: número objetivo de tokens en un solo fragmento
- Mín. Tamaño del fragmento: cantidad mínima de tokens y caracteres en un solo fragmento
- Alfa: tasa de aprendizaje inicial (el tamaño de las actualizaciones de peso en un modelo de aprendizaje automático durante el entrenamiento); el valor predeterminado es 0,025
- Alfa min.: la tasa de aprendizaje disminuirá linealmente hasta alcanzar el alfa mínimo en todas las épocas de inferencia; el valor predeterminado es 0,0001