")
")
")
Embeddings
Los embeddings son vectores que representan documentos completos o fragmentos de ellos en un espacio vectorial continuo. Esta representación numérica es necesaria para inferir similitudes entre documentos de forma eficiente e implementar funciones como la Búsqueda Semántica.
Esto significa que LogicalDOC debe calcular todas estas incrustaciones para los documentos de su repositorio y guardarlas en el Vectors Store, cuya configuración es obligatoria.
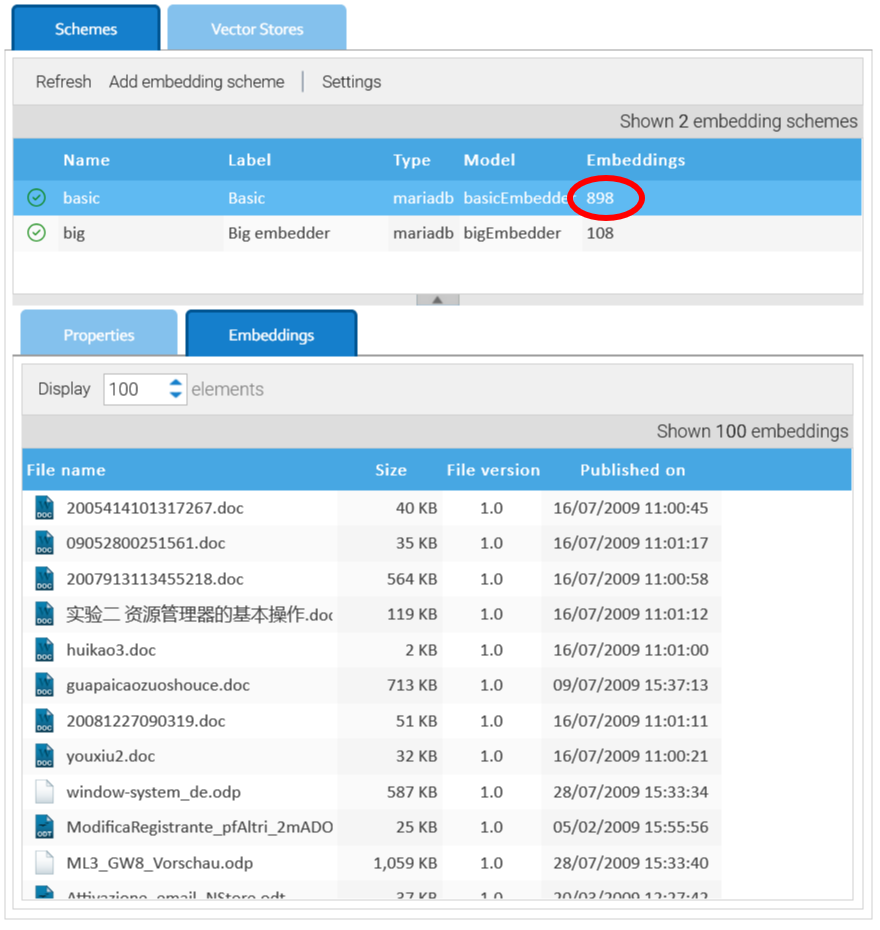
Esquemas de Embedding
El proceso de cálculo de un embedding de un documento no es único, sino que depende del modelo de incrustación que utilice.
En Administración > Inteligencia Artificial > Embeddings, puede gestionar diferentes esquemas de incrustación, cada uno de los cuales indica a LogicalDOC cómo procesar los documentos con un modelo de incrustación específico.
Al crear un nuevo esquema haciendo clic en Añadir esquema de embedding, se le pedirá que especifique uno de los modelos de embedding disponibles.
En el momento de redactar este documento, puede elegir entre los modelos Embedder codificados directamente en LogicalDOC o uno de los modelos de embedding disponibles en ChatGPT.
Otras configuraciones comunes son:
Lote: Número de documentos procesados simultáneamente
Lote de trozos: Cuántos fragmentos se añaden simultáneamente al almacén de vectores
Procesamiento en segundo plano
Al igual que la indexación de texto completo, también el cálculo de los embedding consume mucha CPU, por lo que lo realiza la tarea programada Embedder.
Haga clic en el botón Ajustes para ver algunos parámetros de configuración que regulan el funcionamiento de la tarea.
A medida que los vectores se calculan y se guardan en el almacén de vectores, puede verlos en el contador y en el panel Embeddings.